
개발자는 기록이 답이다
왜 자바 직렬화는 Serializable 인터페이스가 있어야할까? 본문
자바의 신 책에는 DTO에 Serializable를 꼭 구현해야 된다고 되어 있다. 하지만 나는 Spring boot 프로젝트를 했을때 한번도 구현하지 않았는데도, 문제가 없었던것 같다. 어떤 관련이 있는지 "직렬화"라는 개념에 대해서 더 정확히 이해하고자 한다.
본 포스팅을 이해하기 위해서는 사전에 IO에 대한 배경지식이 필요하다.
1. 직렬화란?

직렬화라는 개념은 wiki에서 나오는 것처럼"데이터의 구조"나 객체의 "상태"를 지속되게 만드는 프로세스이다.
우리가 만든 데이터와 객체는 이미 비트로 표현되어 있으며, 해당 객체가 네트워크로 전송되거나 데이터베이스에 저장되기 위해 객체의 상태를 연속적인 바이트 형태로 유지하는 것이 바로 직렬화이다.
여기서 마샬링이라는 개념도 나오는데, 직렬화랑 비슷하지만 더 큰 범위의 변환 방식이다.
마샬링은 다른 시스템 간에 데이터를 교환할때 사용되는데, 주로 이진 형식 또는 구조화된 텍스트 형식으로 변환되어 특정 프로토콜을 따르게 된다.
문제는 네트워크 인프라나 하드 디스크는 비트와 바이트를 이해하긴 하지만, 데이터 객체는 이해하지 못한다.
그래서 데이터 구조를 어떻게 변환할 것인가에 따라 여러 방법이 있다.
- 바이트 스트림 : 직렬화를 통해 객체를 이진 형태로 변환
- JSON, XML : 마샬링을 통해 데이터를 구조화된 텍스트 형식으로 변환
마샬링의 예제이지만, 본 포스팅에서는 직렬화라고 표현하겠습니다.
- google protobuf : 마샬링을 통해 데이터를 이진 형식으로 변환
자바 프로그래밍의 직렬화(Serialization)는 객체의 상태를 바이트 스트림(stream of bytes) 으로 변환하는 메커니즘을 사용한다. 그 반대 개념인 역직렬화(Deserialization)란 바이트로 변환된 데이터를 원래대로 실제 Java 객체를 메모리에 재생성하는 반대 과정이다.

결국 자바에서 직렬화의 목표는 "JVM(Java Virtual Machine 이하 JVM)의 메모리(힙 또는 스택)에 저장된 객체 데이터를 꺼내서 바이트 형태로 변환" 하여 다른 프로세스와의 통신하거나, 외부 저장 매체(데이터베이스나 파일)로 저장하는 것이다. 역직렬화는 다른 컴퓨터에서 이 직렬화된 바이트 형태의 데이터를 객체로 변환해서 다시 JVM메모리에 적재해서 사용는 것으로 보면된다.
메모리에 저장된 객체 데이터는 기본적으로 0과 1로 이루어진 이진 데이터로 표현된다. 이는 컴퓨터 내부의 전자 신호로 구성되어 있다. 이처럼 메모리에 저장된 이진 데이터를 그대로 복사해서 다른 컴퓨터에서 사용한다고 했을 때(예를 들어, 파일로 저장된 뒤 다른 컴퓨터에서 읽을때), 문제가 발생한다. 왜냐하면 이 이진 데이터는 다른 컴퓨터나 프로세스에서 동일한 객체로 해석하기 어렵기 때문이다.
정리하자면, 직렬화라는 것은 메모리에 저장된 객체 데이터를 서로 다른 시스템 또는 프로세스 간에 이해할 수 있는 형태로 변환하는 작업이다.
자바에서는 직렬화를 할때 java.io패키지에 있는 Serializable 인터페이스를 구현해서 사용한다.
2. Java에서의 직렬화
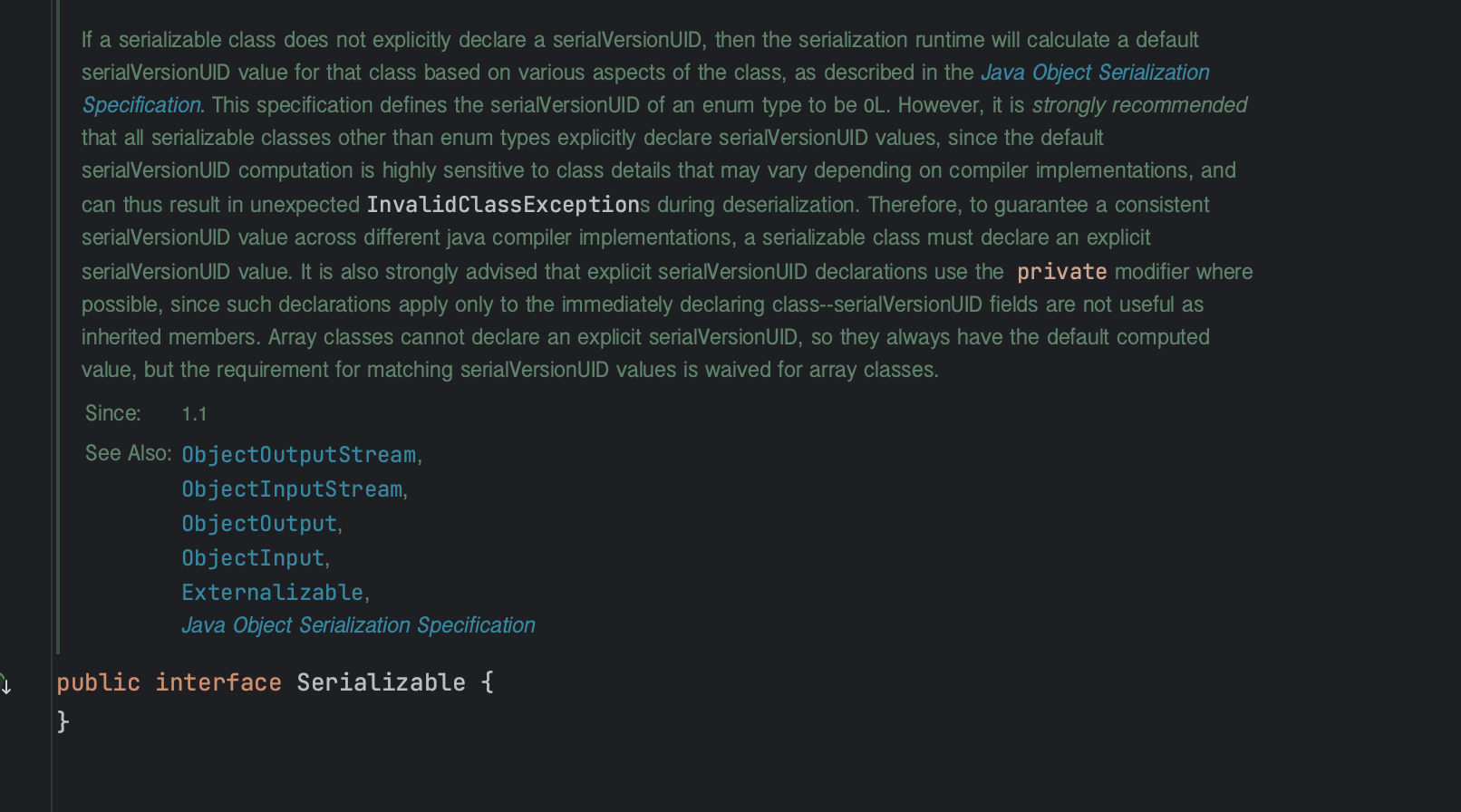
사진을 보면 Serializable 인터페이스는 내부에 어떤 필드나 메소드 선언이 되어있지 않다.
이걸 구현하다고 해서 어떻게 직렬화가 된다는 것일까?
Serializable 인터페이스 는 마커(marker) 인터페이스로서, 메소드가 선언되어있지 않은 것이다.
🤔 마커 인터페이스(Marker Interace)란?
해당 인터페이스를 구현한 클래스가 특정한 특성을 갖고 있다는 것을 나타내기 위해 사용되는 인터페이스
이러한 인터페이스에는 메소드가 선언되어있지 않으며, 해다 인터페이스를 구현한 클래스가 어떤 특별한 동작이나 속성을 지니는지 알리기 위해 표식으로서 사용한다.
대표적인 마커 인터페이스
1. Serializable : 구현한 클래스 객체는 직렬화할 수 있다는 특성
2. Cloneable : 구현한 클래스는 객체의 복제가 가능하다는 특성
자바의 직렬화 메커니즘은 ObjectOutputStream과 ObjectInputStream이라는 클래스를 통해 이루어진다.
이 클래스들은 직렬화된 객체의 데이터를 읽고 쓸 수 있는 기능을 제공한다.
- ObjectOutputStream : 객체를 직렬화하여 스트림에 출력하는 역할
- ObjectInputStream : 스트림으로부터 객체를 읽어 역직렬화하는 역할
이 메커니즘은 객체의 클래스가 Serializable 인터페이스를 구현했는지 여부를 확인하여, JVM에게 해당 객체가 직렬화 가능한 객체인지 여부를 알려준다.
각 클래스에 대한 자바 문서를 살펴보면 아래처럼 되어있다.
먼저 ObjectOutputStream에 대해 살펴보자
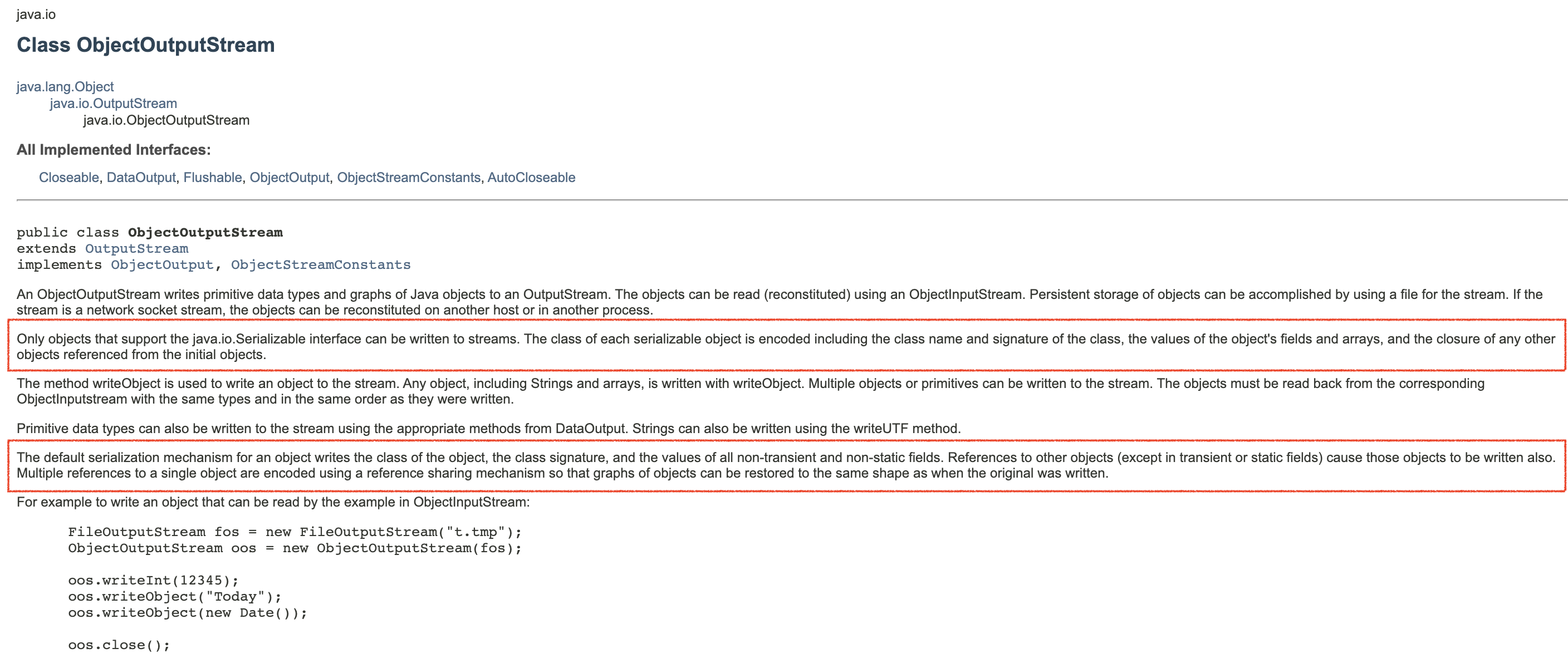
설명이 이것보다는 훨씬 더 길게 있지만, 일단 빨간색으로 네모박스 친 부분만 해석해보자.
java.io.Serializable 인터페이스를 구현한 객체만 스트림에 쓰일 수 있다는 것이다.
이 인터페이스를 구현해서 직렬화 가능한 객체라고 JVM에게 알려주면, 각 객체의 클래스 정보가 인코딩되고, 인코딩에는 클래스 이름, 클래스의 서명(signature), 객체의 필드와 배열의 값, 초기 객체에서 참조된 다른 객체들이 포함된다.
import java.io.Serializable;
class Address implements Serializable {
String street;
String city;
public Address(String street, String city) {
this.street = street;
this.city = city;
}
}
class Person implements Serializable {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
}
// 직렬화 예시
Person person = new Person("John", 30, new Address("123 Main St", "Cityville"));
// 이제 'person' 객체를 직렬화하면, 해당 객체와 참조된 'Address' 객체가 직렬화된다
- 클래스 이름 : Person 클래스, Address 클래스
- 클래스 서명 : 클래스의 구조 설명 (클래스의 메소드, 필드, 상속 등에 대한 정보), 주로 고유 식별자로 사용됨
- 객체의 필드와 배열의 값
- Person클래스 : name, age, address 와 같은 필드
- Address 클래스 : steet, city와 같은 필드
- 초기 객체에서 참조된 다른 객체 : Person객체의 address필드가 Address객체 참조
생성자 및 메소드는 직렬화에 포함되지 않고, 필드의 값만 복원된다.
transient나 static필드를 제외한 모든 필드들은 다른 객체에 대한 참조가 있다면 해당 객체들도 직렬화 되어 스트림에 쓰이도록 한다.
이제 ObjectInputStream에 대해 살펴보자.

ObjectInputStream은 이전에 ObjectOutputStream을 사용해서 바이트로 변환되어 직렬화 객체 데이터를 읽는데 사용된다.
ObjectInputStream은 java.io.Serializable인터페이스를 지원하는 객체만 스트림에서 생성되어 읽을 수 있으며, 해당 스트림으로부터 들어온 객체 유형이 JVM에 있는 클래스와 일치하는지 확인한다.
객체를 역직렬화 할때, 직렬화된 데이터의 유효성 검사를 하고, 객체를 올바르게 복원하기 위한 과정 중 하나이다,
만약 클래스의 버전이나 구조 등이 변경되어 호환성에 문제가 생긴다면 역직렬화 도중에 InvalidClassException와 같은 예외가 발생할 수 있다.
그렇다면 실제 코드상으로 Serializable 인터페이스를 구현했을때, 안했을때 차이가 있는지 확인해보자.
3. ObjectOutputStream과 ObjectInputStream로 확인하기
import java.io.*;
public class Demo implements Serializable {
public int a;
public String b;
public Demo(int a, String b) {
this.a = a;
this.b = b;
}
}
class Test {
public static void main(String[] args) {
Demo object = new Demo(1, "demo");
String filename = "file.ser";
// Serialization
try {
//Saving of object in a file
FileOutputStream file = new FileOutputStream(filename);
ObjectOutputStream out = new ObjectOutputStream(file);
// Method for serialization of object
out.writeObject(object);
out.close();
file.close();
System.out.println("Object has been serialized");
} catch (IOException ex) {
System.out.println("IOException is caught");
ex.printStackTrace();
}
Demo object1 = null;
// Deserialization
try {
// Reading the object from a file
FileInputStream file = new FileInputStream(filename);
ObjectInputStream in = new ObjectInputStream(file);
// Method for deserialization of object
object1 = (Demo) in.readObject();
in.close();
file.close();
System.out.println("Object has been deserialized ");
System.out.println("a = " + object1.a);
System.out.println("b = " + object1.b);
} catch (IOException ex) {
System.out.println("IOException is caught");
ex.printStackTrace();
} catch (ClassNotFoundException ex) {
System.out.println("ClassNotFoundException is caught");
ex.printStackTrace();
}
}
}


위의 코드를 작성하고 실행하면 file.ser이라는 파일이 생기고, 해당 파일에서 객체의 상태를 잘 읽어오는 것을 확인 할 수 있다.
- 직렬화 부분 : FileOutputStream 및 ObjectOutputStream을 사용하여 "Demo객체"를 파일에 직렬화하여 저장한다.
- 역직렬화 부분 : FileInputStream 및 ObjectInputStream을 사용하여 "file.ser 파일"에서 객체를 읽어들인다.
직렬화된 파일 (file.ser)은 객체의 이진 형식으로 저장되므로, 텍스트 에디터에서 읽을 수 있는 형식이 아니기 때문에, 인텔리제이에서 읽을 수 없다. 확장자를 .txt로 변경해서 확인해봐도 사람이 읽을 수 있는 형태가 아니다.

.ser확장자로 저장한 이유는 ava 직렬화된 객체를 나타내는 관례적인 확장자로서 해당 파일이 이진 형식으로 된 데이터임을 나타내기 위함이다. 이로서 직렬화를 하면 사람이 알아보기도 힘든 바이트 형식으로 저장이 된다는 것을 알 수 있다. 해당 파일을 읽기 위해서는 다시 Java프로그램을 통해서 역직렬화해야 한다.
위의 코드에서 implements Serializable 만 제외하고 다시 재실행하면 에러가 나는 것을 확인할 수 있다.
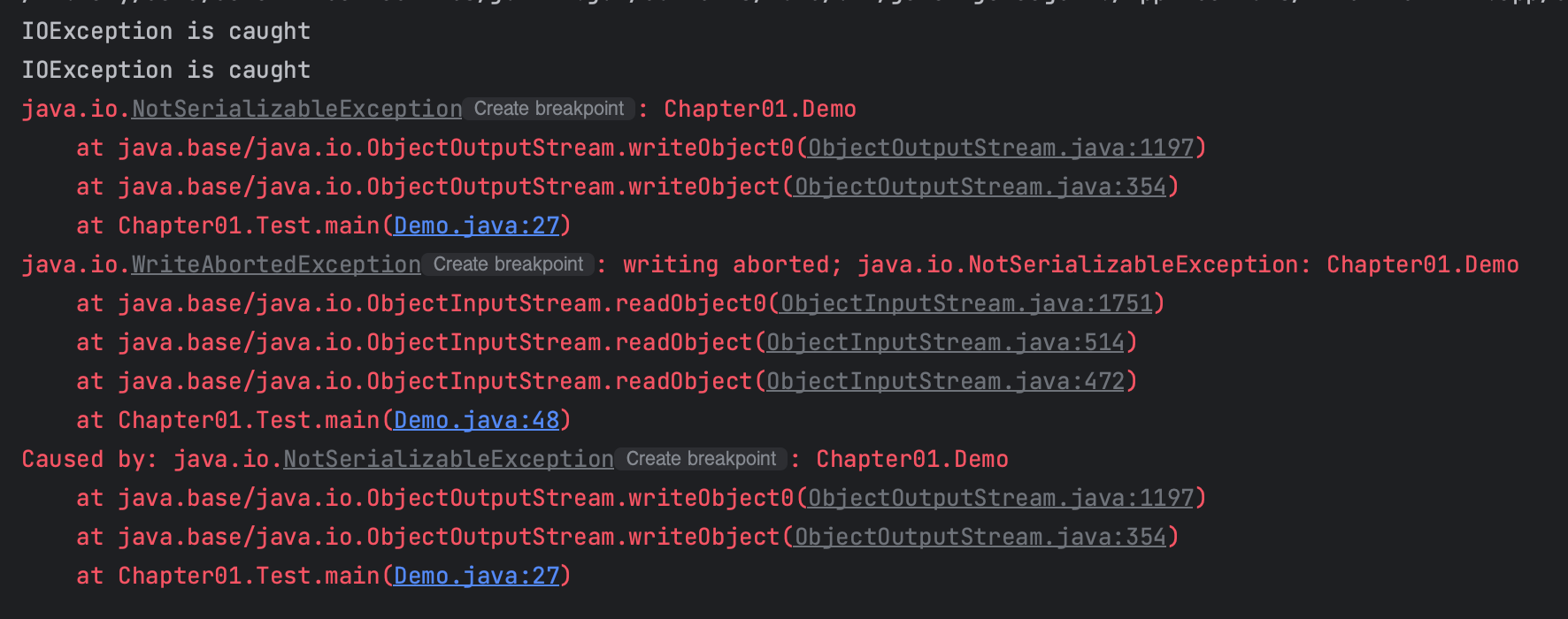
각 라인에서 발생한 에러들에 대해 알아보자.
- 27라인 : writeObject()에서 발생한 NotSerializableException
- writeObject() 메소드는 직렬화를 수행할 때 호출되는 메소드로, 객체를 직렬화하여 파일이나 스트림에 쓰기 위해 사용된다;
- 만약 직렬화하려는 클래스가 Serializable 인터페이스를 구현하지 않았거나, 직렬화할 수 없는 멤버 변수가 있다면 NotSerializableException이 발생한다.
- 48 라인 : readObject()에서 발생한 WriteAbortedException
- readObject() 메소드는 역직렬화를 수행할 때 호출되는 메소드로, 직렬화된 데이터를 읽어와 객체의 상태를 복원하기 위해 사용된다.
- 클래스가 변경되었거나 readObject 메소드에서 예외가 발생하여 객체의 복원이 실패한 경우 WriteAbortedException이 발생한다.
여기서 알 수 있는 것은 각 직렬화와 역직렬화가 writeObject()와 readObject()를 통해 이뤄지는 것을 알 수 있다.
그러면 클래스가 변경되었을 경우 역직렬화 시 발생하는 WriteAbortedException을 위해 코드를 좀 더 변경해보자.
Demo클래스의 인스턴스 변수명인 a를 c로 변경하고 다시 역직렬화 하는 코드이다.
import java.io.*;
public class Demo implements Serializable {
public int c; // 변경된 인스턴스 변수 명
public String b;
public Demo(int a, String b) {
this.c = a;
this.b = b;
}
}
class Test {
public static void main(String[] args) {
Demo object = new Demo(1, "demo");
String filename = "file.ser";
Demo object1 = null;
// Deserialization
try {
// Reading the object from a file
FileInputStream file = new FileInputStream(filename);
ObjectInputStream in = new ObjectInputStream(file);
// Method for deserialization of object
object1 = (Demo) in.readObject();
in.close();
file.close();
System.out.println("Object has been deserialized ");
System.out.println("a = " + object1.c);
System.out.println("b = " + object1.b);
} catch (IOException ex) {
System.out.println("IOException is caught");
ex.printStackTrace();
} catch (ClassNotFoundException ex) {
System.out.println("ClassNotFoundException is caught");
ex.printStackTrace();
}
}
}java.io.InvalidClassException: Chapter01.Demo; local class incompatible: stream classdesc serialVersionUID = -3065943850287111375, local class serialVersionUID = -213333706230190449
readObject()메소드에서 InvalidClassException 에러가 발생했다.
아까는 WriteAbortedException에러가 났는데, 왜 다른 걸까?
InvalidClassException은 일반적으로 직렬화된 클래스의 버전이 현재 클래스와 일치하지 않을 때 발생하는 예외다. 이 예외는 클래스의 시리얼 버전 UID가 서로 다르기 때문에 객체의 역직렬화가 실패했음을 나타낸다.
- InvalidClassException
- 직렬화된 데이터의 클래스 버전 UID와 현재 클래스의 버전 UID가 일치하지 않을 때 발생
- 클래스의 시리얼 버전 UID가 다르면 객체의 역직렬화가 실패하고 이 예외가 발생
- 클래스의 구조가 변경되었을 때, 직렬화된 데이터의 클래스 버전 UID를 변경하지 않고 역직렬화를 시도하면 발생한다.
- WriteAbortedException
- 역직렬화 중에 객체의 상태를 복원하는 동안 오류가 발생했을때 생성
- readObject() 내에서 발생하는 예외를 래핑하고 전달하는 역할을 한다.
- 역직렬화하는 과정에서 직렬화시에 Serializable을 구현하지 않았을 경우 해당 에러가 발생한다.
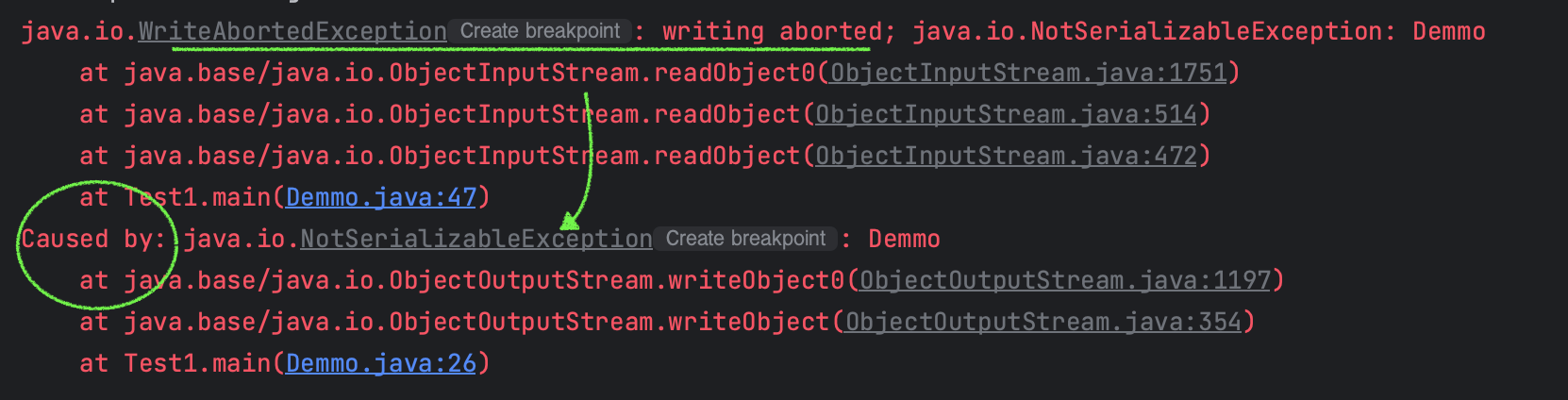
즉, InvalidClassException은 직렬화된 데이터와 현재 클래스의 버전 UID가 일치하지 않을 때 발생하고, WriteAbortedException은 역직렬화 중에 발생하는 예외를 나타낸다.
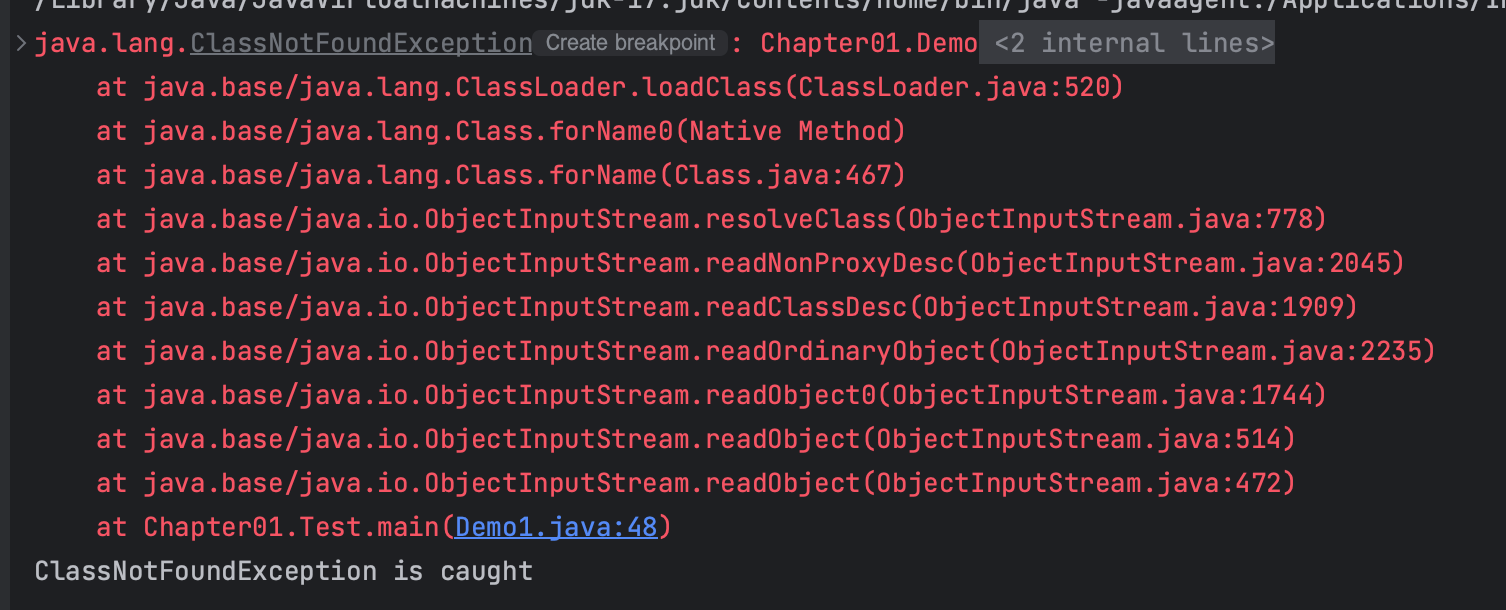
클래스 명을 변경했을 경우에는 해당 클래스를 찾을 수 없다는 ClassNotFoundException 예외가 발생한다.
객체의 상태(필드)를 바이트로 변환하는 것이므로, 메소드와 생성자는 관련이 없지만, 객체의 상태를 담고 있는 클래스 명이 바뀔 경우 해당 클래스를 찾을 수 없다는 에러가 발생하는 것이다.
만약 객체 상태 내부에 외부로 전송하고 싶지 않은 변수가 있는 경우에는 어떻게 할까?
4. transient변수와 static 변수는 직렬화에서 제외
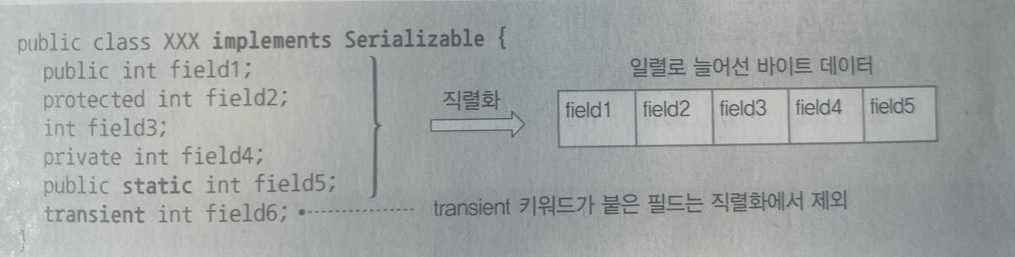
tansient예약어를 선언한 변수는 Serializable의 대상에서 제외된다.
패스워드를 보관하고 있는 변수가 있다고 가정했을때,
이 변수가 외부 저장소에 저장되거나, 네트워크로 전송된다면 보안 상 큰 문제가 발 생할 수 있기 때문이다.
class User implements Serializable {
private String username;
private transient String password; // 직렬화에서 제외되는 변수
// 생성자, getter, setter 등...
}
그렇다면 static은 왜 제외되는 것일까?
static 예약어는 객체에 소속된 게 아니라 클래스에 소속된 것이기 때문에 객체의 상태를 직렬화하는 과정에 포함이 되지 않는다.
즉, static 변수가 객체의 상태가 아닌 클래스의 상태를 나타내기 때문에 static 변수는 직렬화 과정에서 포함되지 않는다.
지금까지 클래스 내부의 상태가 직렬화되는 것(인스턴스 변수)과 아닌 것(메소드,생성자, transient변수, static변수)에 대해 알아봤다.
그런데 위에서 계속 에러나는 상황을 보면 직렬화가 클래스 변경에 굉장히 민감하다는 것을 알 수 있다.
개발하다보면 클래스 상태를 변경하는 경우게 굉장히 많은데,
이렇게 클래스 상태와 구조를 변경할때마다 역직렬화를 실패한다면 어떻게 해야할까?
그럴때 사용하는 것이 SerialVersionUID이다.
5. SerialVersionUID
직렬화된 객체를 역직렬화 할 때 직렬화했을 때와 같은 클래스를 사용해야 한다.
클래스 명이 같더라도 클래스의 내용이 변경되면 역직렬화는 실패하며 InvalidClassException 예외가 발생하는 것을 위에서 확인해봤다.
serialVersionUID은 같은 클래스 임을 알려주는 식별자 역할을 한다.
private static final long serialVersionUID = 1L;
그런데, 이전 코드에서는 serialVersionUID 를 지정하지 않았는데도 역직렬화가 잘 되었는데, 왜 일까?
Serializable 인터페이스를 구현한 클래스는 컴파일 할때 자동으로 serialVersionUID 정적필드가 추가된다.
문제는 클래스를 재컴파일 하면 serialVersionUID의 값이 달리진 다는 것이다.
위에서 발생했던 예외를 다시 한번 살펴보자. 해당 예외는 인스턴스 변수명을 a에서 c로 변경했을때 발생했던 예외이다.
java.io.InvalidClassException: Chapter01.Demo; local class incompatible:
stream classdesc serialVersionUID = -3065943850287111375,
local class serialVersionUID = -213333706230190449- stream classdesc serialVersionUID : 이전에 직렬화된 클래스의 serialVersionUID
- local class serialVersionUID : 현재 클래스의 serialVersionUID
이에 대한 해결책으로는 기존에 파일에 저장된 Demo 객체를 복원하기 위해, 기존의 serialVersionUID 값인 -3065943850287111375L를 현재 클래스에 명시적으로 설정해야 한다.
private static final long serialVersionUID = -3065943850287111375L;
따라서 클래스를 생성했을때 부터 serialVersionUID를 명시적으로 선언해야 한다.
하지만 클래스의 구조가 변경되어서(변수명 변경) 이전 버전의 클래스로 저장된 객체를 현재 클래스로 역직렬화하면 데이터 유실이 발생할 수 있다. 즉, 변수명이 변경(a → c)되었기 때문에 이전 버전에서 사용된 변수명을 찾을 수 없기 때문이다.
따라서 클래스를 생성할 때부터 serialVersionUID를 명시적으로 선언하해야지 클래스의 구조가 변경되어도 호환성을 유지할 수 있다.
이 serialVersionUID은 클래스마다 다른 값을 가져야 다른 클래스와 충돌이 나지 않는다.
그래서 개발자가 임의로 값을 정하는 것보다 serialVersionUID값을 자동으로 생성시켜주는 serialver.exe의 명령어를 사용하는게 좋다고한다.
serialver [-classpath classpath] [-show] [classname…]
그런데 이렇게 제약사항이 많은데 자바 직렬화 과연 좋은게 맞을까?
자바 직렬화는 자바 프로그래밍 끼리만 호환이 된다는 단점이 있으며,
심지어 자바 프로그램끼리도 클래스 구조 변경 등에 대한 여러 제약 사항 때문에 100%호환이 된다고 할 수가 없다.
차라리 최근에 많이 사용하는 Json, csv, xml로 직렬화 하는게 더 나을 것같다.
- JSON : 구조적인 데이터를 전달하는 API 시스템 등에서 많이 사용됨
- CSV : 표 형태의 데이터에서 많이 사용됨
결론
Spring Boot에서 클라이언트와 통신하면서 어떻게 JSON을 받아올 수 있는가는 jackson 라이브러리에서 ObjectMapper를 이용해서 네트워크로 전송된 데이터를 Json 으로 변환해준다고 한다.
사실 자바의 직렬화에 이어서 Spring boot로 이어지고 싶었지만, 정확하게 파악하진 못해서 링크로 대체하고자 한다.
Serializable 외에도 여러 직렬화 방법이 존재한다는 것을 알게 되었다.
지금까지 개발한 API 통신이나 데이터베이스에 데이터를 저장하는 과정에서 "직렬화" 개념이 사용된다.
해당 과정에는 Java 직렬화뿐만 아니라 다양한 직렬화 방법을 포함한다.
Java 직렬화는 Serializable을 사용하여 객체를 바이트 형태로 변환하는 방법이지만, 이에는 여러 제약 사항이 따른다.
Java에서 직렬화하는 방법 중 바이트 형태로 변환해주는 Serializable은 여러 제약 사항이 많고, 최근에는 Json 직렬화를 대부분 많이 사용한다는 것과 연결고리를 지을 수 있었다.
참고 문서
마샬링(Marshalling) vs 직렬화(Serialization)
http://www.soen.kr/book/java/book/21-3.htm
https://pabeba.tistory.com/127
스프링 MVC - HttpMessageConverters
'언어 > Java' 카테고리의 다른 글
| Prefix를 빠르게 검색할때, MySQL에서 Index가 있다면 Java에서는 트라이(Trie)를 사용하자. (0) | 2024.06.29 |
|---|---|
| Exception Wrapping vs Rethrowing (0) | 2024.03.25 |
| Executor, ExecutorService, Executors 동작원리 ( + ThreadPoolExecutor 디버깅) (1) | 2024.01.26 |
| HashMap이 동작하는 원리를 파헤쳐보자 + putVal메소드 디버깅 (0) | 2024.01.21 |
| [Java] String 덧셈 연산의 컴파일 최적화에 대해 알아보자 (0) | 2024.01.12 |


