
개발자는 기록이 답이다
HashMap이 동작하는 원리를 파헤쳐보자 + putVal메소드 디버깅 본문
HashMap은 Map인터페이스 기반의 Hashtable 구현체라고 알려져 있다.
구글링해서 많은 자료들을 찾아봤지만,
CS에서 사용하는 HashTable이라는 개념과 Java코드로 구현한 Hashtable, HashMap을 같이 엮어서 생각해보려니까
bucket, entry, node 등 용어들이 헷갈린다. 그래서 직접 디버깅하면서 원리를 파악해보고자 한다.
(본 포스팅을 보기 전에 우선 동일성과 동등성 개념에 대한 이해가 있어야 한다)
1. HashSet은 중복을 허용하지 않는다
HashSet의 특징이라고 하면 순서가 중요하지 않고 중복을 허용하지 않는 자료구조라고 많이 알고 있다.
그런데 이 "중복"의 기준이 뭘까?
Person클래스를 만들어서 HashSet에 데이터를 저장할때 add()메소드를 사용할 것이다.
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person person)) return false;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}public class Sample {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person("세진",30));
}
}
이때 add()메소드를 들어가보면 HashMap의 put으로 데이터를 저장하는 것을 볼 수 있다.


map.put("세진", DummyValue)
add()의 매개변수로 들어온 String타입을 key로 저장하고, value는 Object타입의 dummy value를 저장하는 것이다.
이것을 보고 Map은 키의 중복은 허용하지 않고, value의 중복은 허용한다는 것이 떠올라야한다.
그러면 키의 중복을 어떻게 판단하는지 알아보기 위해 본격적으로 HashMap을 파헤쳐보자.
2. HashMap의 초기화와 버킷 생성
HashMap은 배열로 되어 있어서 삽입, 삭제, 갱신, 탐색에 상수 시간 O(1)이 걸린다고 한다.
이 말은 데이터의 크기에 상관없이 일정한 시간내에 기능을 수행할 수 있다는 것이다.
그러면 HashMap 객체를 생성해보자.
HashMap<Person, String> map = new HashMap<>();
HashMap의 매개변수 없는 생성자를 살펴보면 기본 초기 용량 16과 기본 로드팩터 0.75를 사용해서 HashMap객체를 사용한다고 나온다. 로드팩터는 해시 테이블이 자동으로 증가되기 전에 허용되는 꽉참의 정도를 의미한다.
(본 포스팅에서 로드팩터에 대해서는 설명하지 않는다.)

위에서 배열로 되어있다고 언급했는데 도대체 그 배열은 어디있는 것일까?
HashMap 필드로 Node라는 클래스 배열로 table이 선언되어 있다.
이 table이 버킷을 말하는 것으로 실제로 데이터가 추가되는 put()메서드가 호출될때 버킷도 같이 생성된다.

Node는 HashMap의 이너클래스로 아래처럼 정의되어 있다.
- hash : 키의 해시코드(hash()메서드 결과 저장 - Override한 hashCode값이 아니다)
- key : 버킷에 저장된 키
- value : 키에 매핑된 값
- next : 해시 충돌과 연관된 필드

그러면 데이터를 저장할 준비를 하고, put()메소드를 들여다보자.
put()메소드는 내부적으로 1) hash()메서드를 호출한뒤, 2) putVal()메소드를 호출한다.
public static void main(String[] args) {
HashMap<Person, String> map = new HashMap<>();
map.put(new Person("세진",30),"person1");
map.put(new Person("세진",28),"person2");
map.put(new Person("세진",30),"person3"); // person1과 동등한 객체
System.out.println(map);
}
먼저 hash()메서드 부터 살펴보자.

키의 hashCode()메서드와 비트 연산을 이용해서 키에 대한 새로운 해시 코드를 생성한다.
int h = key.hashCode(); // 키의 해시코드 추출
int shiftR = h >>> 16; // h의 비트를 오른쪽으로 16만큼 이동
int xor = h ^ shiftR; // 비트 XOR 연산, 비트를 서로 섞어준다Person key = new Person("세진", 30);
int h = key.hashCode();// 키의 해시코드 추출 : 49137107
System.out.println("HashCode in Binary: " + Integer.toBinaryString(h));
int shiftR = h >>> 16; // h의 비트를 오른쪽으로 16만큼 이동 : 749
System.out.println(" shiftR in Binary: " + Integer.toBinaryString(shiftR));
int xor = h ^ shiftR; // 비트 XOR 연산, 비트를 서로 섞어준다 : 49137470
System.out.println(" xor in Binary: " + Integer.toBinaryString(xor));
///OUTPUT
HashCode in Binary: 10111011011100010111010011
shiftR in Binary: 1011101101
xor in Binary: 10111011011100011100111110
키에서 오버라이딩한 hashCode()메서드의 반환값을 hash로 사용하는 것이 아니라, HashMap내부적으로 추가적인 비트 연산을 한 번 더 거친뒤 hash로 사용된다.
그 이유는 해시 코드의 분포를 개선하고 해시 충돌을 최소화하고자 함이다.
그 다음으로 putVal()메소드를 살펴보자.
putVal()메소드는 크게 3가지 경우의 조건문으로 나뉜다.

Node<K,V>[] tab; Node<K,V> p; int n, i;
- Node<K,V>[] tab : HashMap의 노드를 저장하는 배열, 즉 버킷을 의미 (현재 사용중인 해시테이블을 참조)
- Node<K,V> p : 키와 값을 가진 노드
- int n : 버킷의 길이(용량)
- int i : 버킷에서 조작중 인덱스
(1) 현재 table이거나 길이가 0이면 resizie()메소드를 호출해서 새로운 table 할당
- 처음 데이터를 넣을때 테이블을 생성하기 위해 실행
(2) 현재 Index를 계산하고 해당 table[i]에 있는 노드 p가 null이면 새로운 Node 할당
- 현재 버킷에 처음 들어가는 데이터일 경우 실행
(3) 그 외 경우
- value를 대체하거나, 해시충돌이 발생할때 실행
어느정도 흐름을 파악했다면 이제 첫번째 데이터를 넣고, 디버깅을 해보자.
map.put(new Person("세진",30),"person1");

첫번째 데이터 들어갈때 아직 table이 초기화 되지 않은 상태이기 때문에 1번 조건문에 들어간다.
(tab = table) == null || (n = tab.length) == 0
HashMap 클래스의 필드인 table은 객체가 생성될 때 초기값이 null이기 때문에 true이다.
n = (tab = resize()).length; // 16
이후 resize()메소드를 호출해서 table에 새로운 테이블을 할당하고, n은 tab의 길이를 할당한다.
그러면 resize()메소드 호출이 어떻게 되는지 살펴보자

1) 현재 사용중인 테이블의 용량과 임계값을 old변수에 할당하고, new 용량과 임계값 변수를 선언한다.
Node<K,V>[] oldTab = table; // 현재 사용중인 테이블을 oldTabl변수에 할당한다
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 현재 사용중인 테이블의 길이를 oldCap변수에 저장하고, 테이블이 null일 경우 0으로 간주한다
int oldThr = threshold; // 현재 사용중인 임계값을 oldThr변수에 저장한다
int newCap, newThr = 0; // 새로운 테이블의 길이(newCap)과 임계값(newThr)를 선언하고, newThr의 초기값은 0이다.
2) 새로운 길이를 기본 초기 용량으로, 임계값은 기본 초기 용량 * 로드팩터를 한 값으로 할당한다.
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
- 왼쪽 비트 시프트 연산 (<<) : 특정 수를 이진수로 나타냈을 때 각 비트를 왼쪽으로 주어진 횟수만큼 이동시킨다.
- 아래는 왼쪽 비트 시프트 연산의 과정을 알기 쉽게 표현한 코드이다.
// 1 in Binary:
String binaryString1 = String.format("%4s", Integer.toBinaryString(1)).replace(' ', '0');
System.out.println("1 in Binary: " + binaryString1); // 0001
// 1 << 4:
int result = 1 << 4;
String binaryStringResult = String.format("%5s", Integer.toBinaryString(result)).replace(' ', '0');
System.out.println("1 << 4: " + binaryStringResult); // 10000
- newThr = 16의 75%인 12이 할당 (16 * 0.75f)
3) 임계값을 새로 계산된 값으로 할당하고, newCap의 용량만큼 새로운 테이블 생성한다.
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 새로 생성된 테이블을 현재 사용중인 테이블로 업데이트(리사이징 Or 초기화시 사용)

- threshold : resize(크기 조정)이 필요한 시점의 임계값 ( 용량 * 로드팩터 )
- 임계값은 HashMap의 크기에 따라 동적으로 저절되고, 해시 충돌 등의 상황에서 동적으로 조절된다.
3번을 디버그 모드 결과를 캡쳐한 사진을 보면 HashMap$Node[16]@747 라고 새로운 배열의 내용이 나온다.
(길이가 16인 Node배열이며, 이 배열의 해시 코드가 747인 객체라는 것이다.)

- HashMap$Node: 이 배열의 원소 타입은 HashMap의 Node 클래스이다
- [16]: 배열의 길이는 16입니다. 즉, 16개의 원소를 가지고 있는 배열
- @747: 이 숫자는 해당 객체의 해시 코드를 나타낸다. 실제로는 매번 다를 수 있다.
- (아래에서 계속 나올텐데, 포스팅을 위해 여러번 디버깅 과정을 거쳐서 숫자가 매번 다를 것이다)



이 과정까지 오면 버킷이 생성된다.
정리
- 기본 생성자를 이용하여 해시 맵을 생성하면 버킷의 용량이 결정되지 않음
- 키의 hashCode() 메서드는 HashMap의 hash() 메서드에서 추가 처리를 위해 사용 됨
- put() 메서드를 호출했는데 버킷이 없다면, resize() 메서드를 호출하여 용량이 16인 버킷 생성
2. HashMap에 데이터 저장하기 - 1 ( 첫번째 데이터 )
아직까지 버킷을 생성했을 뿐, 데이터를 버킷에 넣지는 않았다.
그렇다면 이제 데이터가 저장되는 과정을 살펴보자.
map.put(new Person("세진",30),"person1");
위에서 봤던 putVal()메소드의 파란색 네모박스의 2번째 조건문에 들어간다.
table 변수는 위의 과정을 거쳐서 크기가 16인 Node 배열로 초기화되었다는 것을 기억하자
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
인덱스 i는 버킷 용량 - 1(n-1)과 키의 해시코드(hash)의 AND연산으로 할당된다.
i = (n - 1) & hash
i = 15 & 49137470
계산 결과 인덱스는 14로 결정되고, 현재 tab[14]에 들어있는 원소가 없으므로 버킷에 노드를 삽입하는 코드가 실행된다


현재 tab[14]에 들어있는 원소가 없으므로, 버킷에 노드를 삽입하는 코드가 실행된다
if((p = tab[14]) == null)if((p = null) == null)if(null == null) // true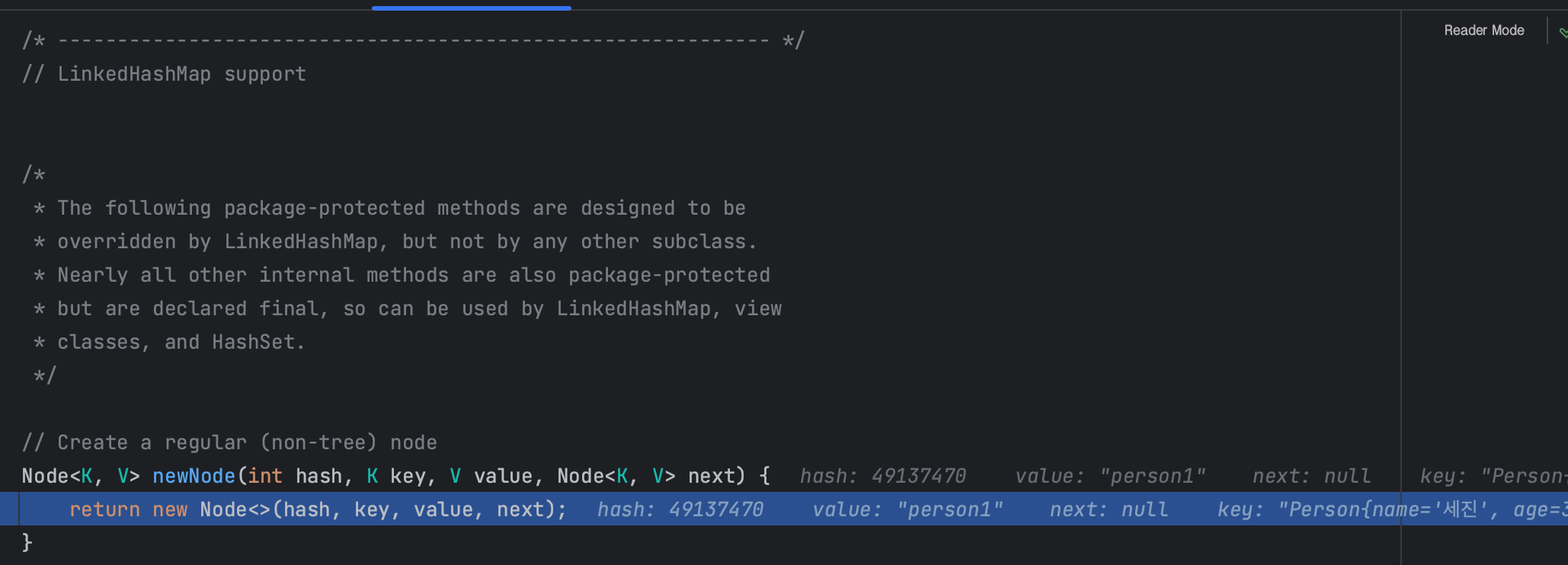
tab[i] = newNode(hash, key, value, null);
tab[14] = newNode(49137470, Person{name='세진', age=30}, person1, null);

이를 그림으로 표현하면 아래와 같다.

크기가 16인 버킷의 14번 인덱스에 새로운 노드가 할당되었다.
그리고 초록색 네모박스 3번 아래 있는 나머지 코드가 실행되면서 첫 번째 데이터 저장이 완료된다.
++modCount; // HashMap 수정 회수 증가
if (++size > threshold) // HashMap의 size를 증가시키고, 임게값 초과시 resize()호출
resize();
afterNodeInsertion(evict); // 노드가 삽입된 이후 수행할 추가작업
return null; // 새로운 값이 매핑된 경우 null반환
정리
- bucket의 인덱스를 계산해서 해당 인덱스에 Node를 할당한다.
- Node가 할당되면 HashMap의 size가 증가한다
3. HashMap에 데이터 저장하기 - 2 ( 다른 두번째 데이터 )
그러면 두 번째 데이터를 넣으면 어떻게 저장되는지도 살펴보자
map.put(new Person("세진",28),"person2");
빨간색 네모박스 1번은 이미 버킷이 생성된 상태이기 때문에 건너뛰고,
파란색 네모박스인 2번 조건문에서 걸리는데, tab[12]가 현재 null일 상태이기 때문에, 새로운 노드가 할당되고,
마찬가지로 나머지 코드가 실행되면서 modCount랑 size가 하나씩 증가한다.




정리
- 2번과 동일하게 동작하고, hash와 인덱스를 찾는 작업을 거친 뒤 해당 노드를 할당한다
4. HashMap에 데이터 저장하기 - 3 ( 동등한 세번째 데이터, value 대체)
그렇다면 동일한 해시와 동등한 내용의 key를 가진 데이터를 저장할땐 어떻게 동작하는지 살펴보자.
map.put(new Person("세진",30),"person3"); // person1과 동등한 객체 추가
빨간색, 파란색 네모박스를 건너뛰고 드디어 초록색 네모박스인 3번 else문으로 오게 된다.
else문도 아래 사진처럼 크게 3가지로 나뉜다.

(1) 기존 노드와 해시코드가 같고 키가 동등한 경우 e에 기존 노드를 할당
- 동등한 객체일 경우, 값(value) 대체
(2) TreeNode 클래스인 경우 트리 기반의 삽입 로직을 수행
- 해시 충돌났는데, p가 트리노드 기반일 경우
(3) 연결 리스트인 경우 반복문을 통해 노드를 탐색하면서 새로운 노드를 추가
- 해시 충돌났는데, P가 트리노드 기반이 아닐 경우(연결리스트)


else문 중에서 1번째 조건문에서 걸렸는데 이 부분은 기존에 이미 존재하던 노드와 매핑된 경우를 의미한다.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
여기서 p라는 것 파란색 네모박스의 if조건문에서 할당한 된 노드를 말한다.
if ((p = tab[i = (n - 1) & hash]) == null) // 위에서 설명한 파란색 네모박스 2번 조건문p = tab[14]
아직 resize()되지 않았으니, n은 여전히 16이고, 1번째 데이터와 동등한 객체를 추가했으니 hash도 똑같아서 p는 tab[14]번째 노드이다.
p.hash == hashperson1.hash(49137470) == hash(49137470)
기존 노드 p는 person1이고, 동등한 객체를 추가했으므로 해시코드가 똑같아서 true이다
((k = p.key) == key || (key != null && key.equals(k)))
위의 코드는 key의 동일성, 동등성 비교를 하는 부분이다.
객체의 메모리 위치가 같지 않으므로 동일성은 false, 객체의 내용(Person{name='세진', age=30}) 이 같으므로 true라서
변수e에 기존 노드를 할당한다.

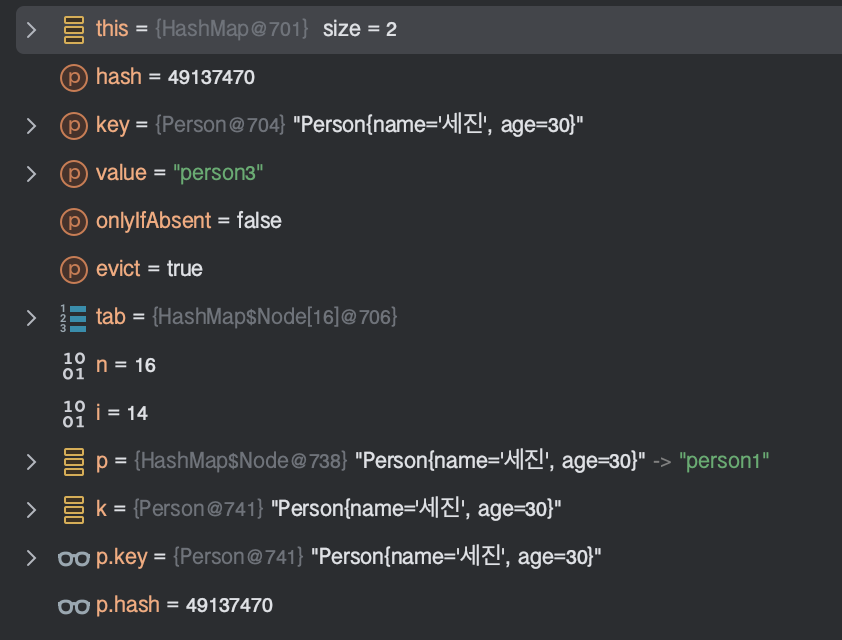

그리고 다음 코드로 넘어가는데. e가 null이 아닐 경우 값(value)을 대체해주는 과정을 거친다.
동등한 키에 대해서 value를 person1 에서 person3으로 대체한다.
그래서 map.put()메소드로 기존 값(value)이 대체될때, 반환 값으로 기존(value) 값이 나오는 이유가 바로 oldValue가 리턴되는 부분이다.



정리
- 동등한 내용와 동일한 해시코드를 가진 객체를 key로 추가할 경우, 기존 노드를 찾아서 값(value)을 대체한다
5. HashMap에 데이터 저장하기 - 4 (해시충돌)
동등한 객체를 집어넣을때는 값(value)이 대체되는것을 확인했다.
그러면 해시가 똑같고 내용은 다른 상황에서 어떻게 동작할까? (혹은 hashCode오버라이딩O, equals오버라이딩x)
결론부터 말하자면 각 Node를 연결리스트로 저장한 뒤,
연결리스트의 길이가 일정 임계값을 넘으면 해당 버킷의 노드들을 Tree구조로 변환한다.
위에서 HashMap은 상수 시간이 걸린다고 했던 걸 기억하는가?
연결리스트의 경우 각 노드가 다음 노드를 가르키는 구조로 되어있어 특정 노드를 찾기 위해서는 순차적으로 탐색해야하므로 O(n) 시간이 걸린다. 레드 블랙 트리 구조는 탐색에 O(log n)시간이 걸리기 때문에 효율적이다. (본 포스팅에서 트리구조가 왜 성능이 좋은지 다루지 않는다)
그러면 코드상으로 어떻게 동작되는건지 살펴보자.
Person클래스의 오버라이드 된 hashCode에서 Objects.hash()를 지워서 임시로 1을 반환하도록 만들고, person4객체를 추가해보자.
(해시는 똑같고, 내용은 다른 상황 = 해시충돌 상황을 만들기 위함)
※ 여기서 기억해야할 점은 hashCode 반환값이 동일하다고 해시 충돌이 일어나는게 아니라, hashCode반환값을 가지고 hash()함수를 통해서 나온 해시 값이 같을 경우 충돌이 난다는 것이다.
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person person)) return false;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return 1;
}
}map.put(new Person("세진",100),"person4"); // 해시코드는 같고, 동등하진 않은 객체
일단 else문부터 시작할 것이고, 해시 충돌이 난 상황이라 else문안의 1번 조건문은 건너뛰고, 트리노드 기반이 아니기 때문에 2번 조건문도 건너뛰고 else문 안에 else문인 3번으로 올것이다
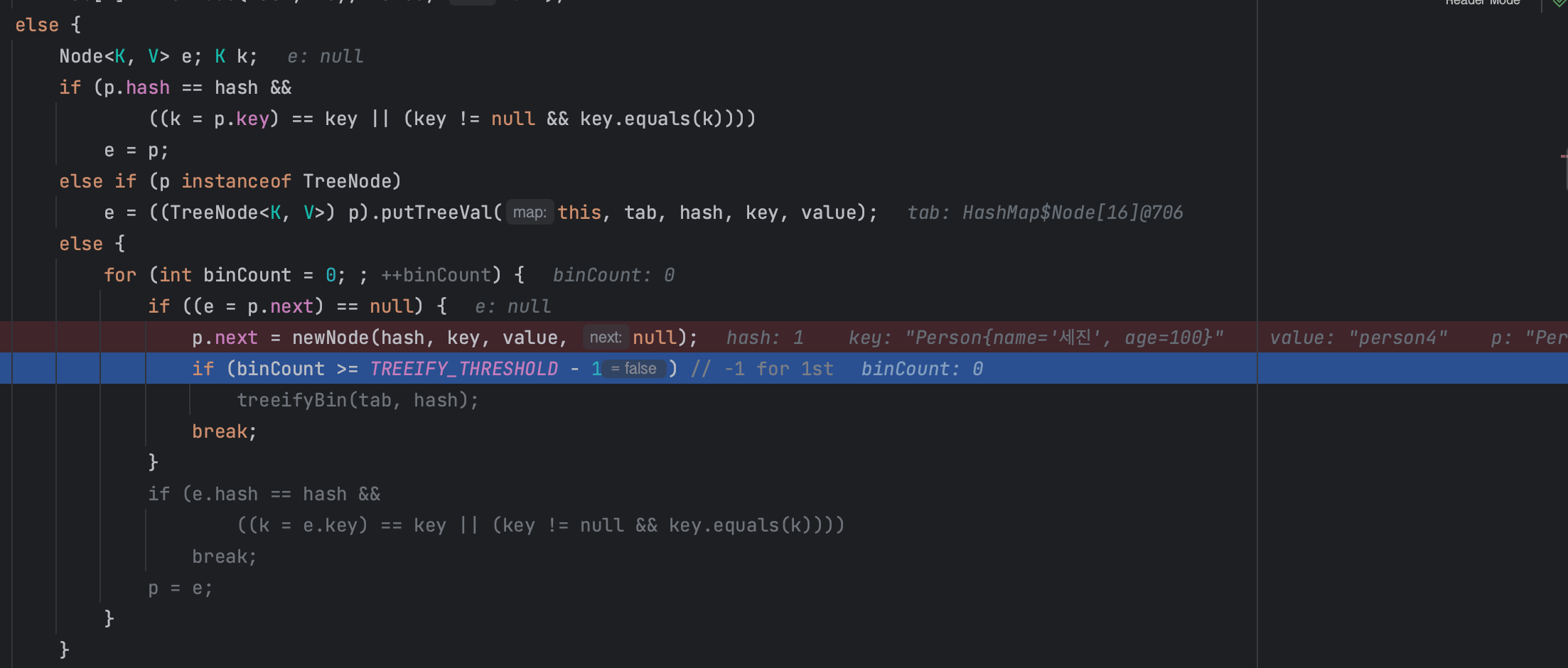
먼저 else문의 처음 시작부터 차근차근 보도록하자.
for (int binCount = 0; ; ++binCount) {
bitCount는 연결리스트의 노드 개수를 가르킨다. 0부터 시작해서 연결 리스트를 순회하는 반복문으로서 사용된다.
기존에 버킷 14번 인덱스에 저장된 노드가 p를 가르킨다.
(사진에서 인덱스가 1, hash도 1이라고 나오는데, 해시충돌을 가정하기 위해 임시로 hashCode를 조작한 상황이므로 아래 상황이라고 가정하자)

현재 노드p의 next를 e변수에 할당한 뒤, null인 상황이므로 next에 새로운 노드를 생성한다.
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
...
}p.next = newNode(1, Person{name='세진', age=100}, person4, null);

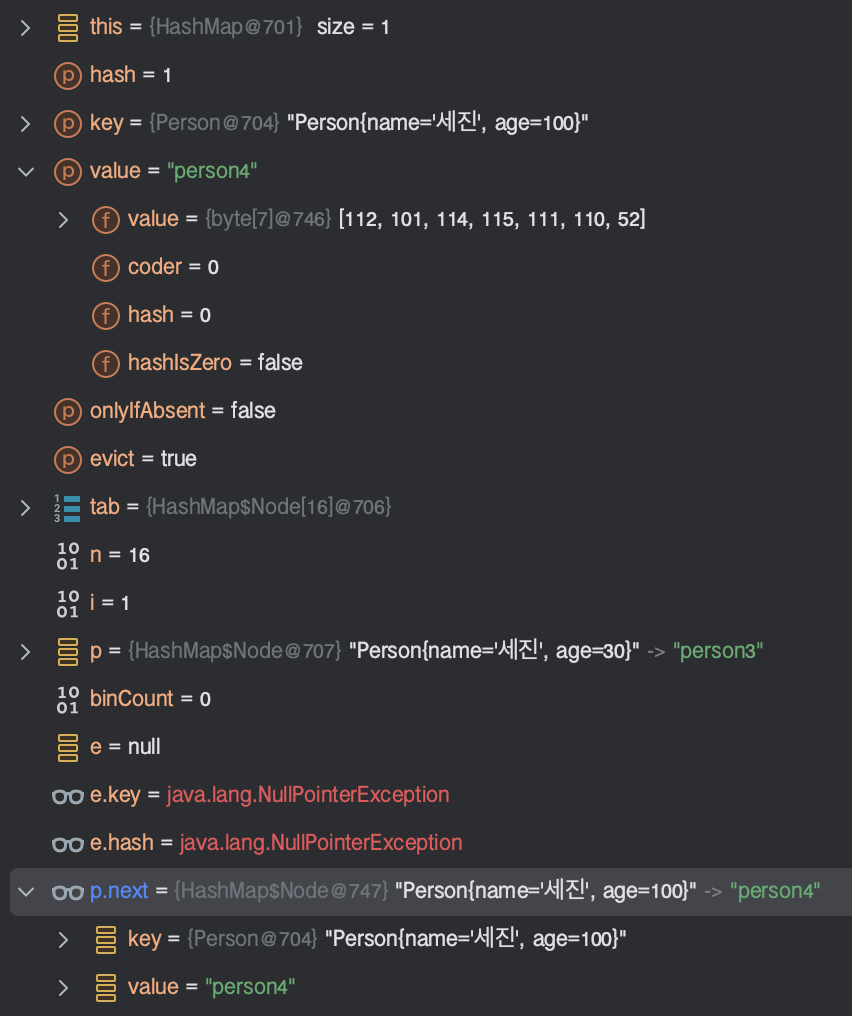
Node클래스의 구현이 왜 연결리스트인건가?
next필드로 여러 Node 인스턴스가 서로를 참조함으로써 연결리스트가 형성된다.
이렇게 next에 할당된 노드를 그림으로 그리면 아래와 같다.
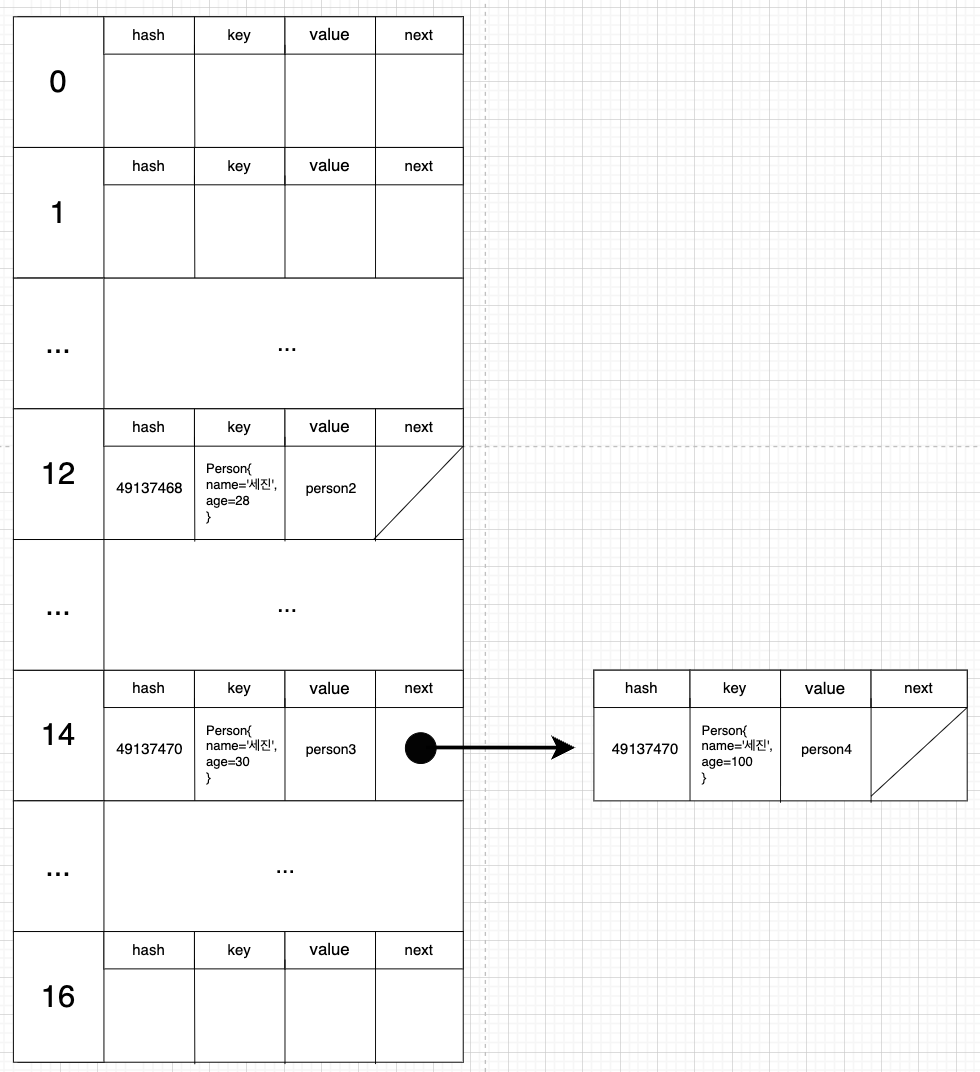
이렇게 해시충돌로 인해 똑같한 해시코드를 가진 노드들이 한 버킷에 연결리스트로 저장된다.
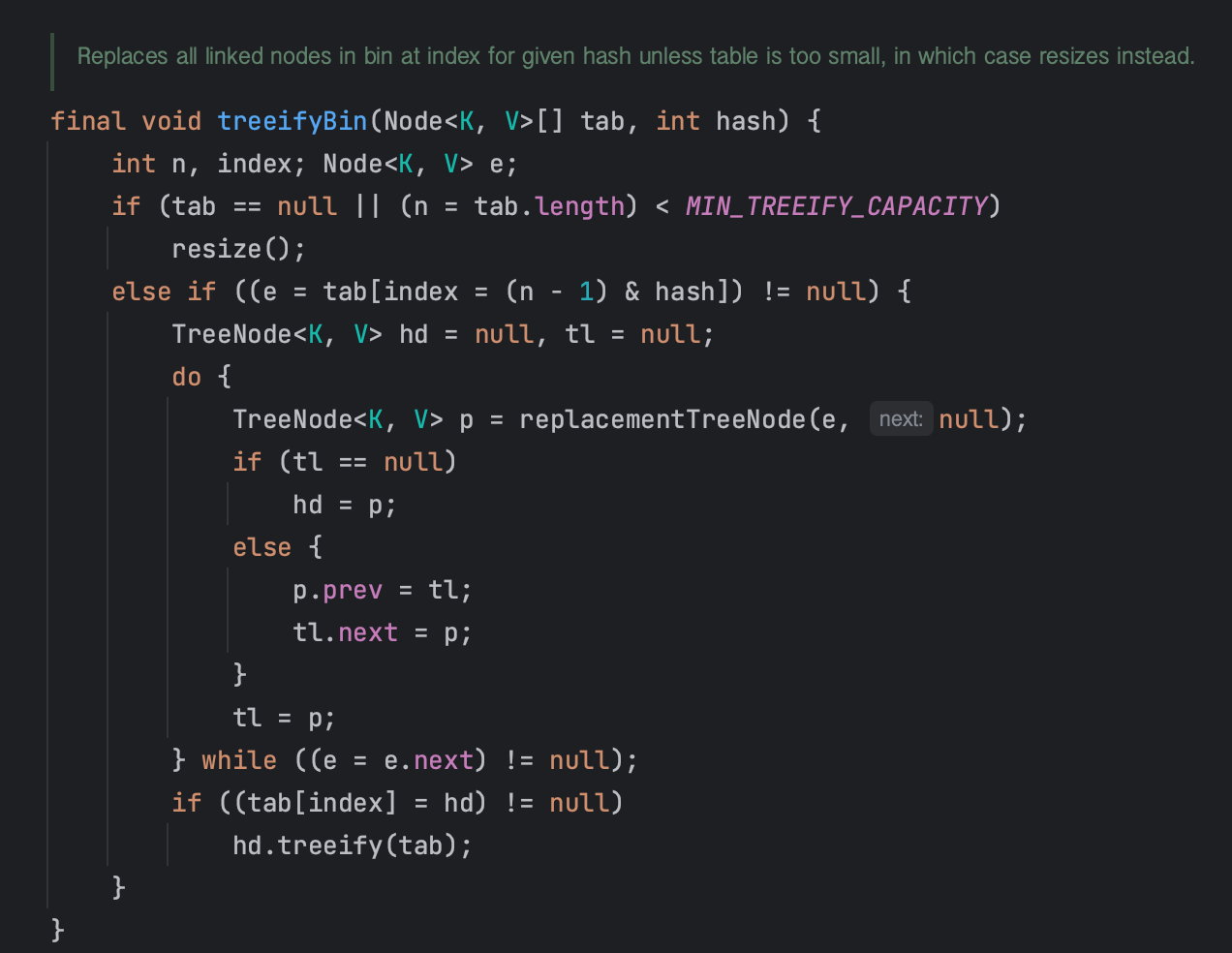
하지만 충돌이 지속되어서 연결리스트의 길이가 (TREEIFY_THRESHOLD -1)가 될 경우 경우, 버킷의 노드들을 트리로 변환한다
// 연결 리스트의 길이가 일정 임계값을 초과하면 트리로 변환
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
현재 노드의 next가 null인 경우를 찾기 위해 연결리스트를 순회할때 binCount가 증가한다.
binCount가 8을 넘으면 treeifyBin() 메소드가 실행되면서 기존의 Node를 TreeNode형태로 변환한다.
원래 자바 7버전까지는 노드를 연결리스트로만 저장해서 O(n)의 시간 복잡도가 소요됐었다. 하지만 Java 8버전 부터 특정 threshold를 초과할 경우 레드 블랙 트리로 구조가 변경되면서 O(logN)시간 복잡도가 소요된다.
관련 내용은 오라클 공식 문서에 적혀져 있으므로, 아래는 해당 내용을 일부 발췌한 캡쳐본이다.

정리
- 해시 충돌은 불가피하다.
- 해시 충돌시 연결리스트로 Node를 저장하고. 일정 길이를 초과해서 저장되면 레드 블랙 트리 구조로 변환된다. 또한 hash가 삭제되서 TREEIFY_THRESHOLD보다 길이가 작아지면 다시 연결리스트 기반으로 돌아간다.
- 해시 충돌 방법에는 Separate Chaining과 Open Addressing(linear probing) 방식 2가지가 있는데, Java에서는 Separate Chaining방식만 사용한다.
- 해시가 충돌하지 않는다는 전제하에 보통 탐색에 O(1)의 상수시간이 걸리지만, 해시 충돌이 났을 경우 체이닝으로 연결된 리스트를 모두 탐색해야 하므로 O(n)까지 늘어난다. 하지만 java 8버전 부터 일정 길이 이상 시 레드 블랙 트리구조로 변경될때는 O(logN)시간이 걸린다.
마치며
HashMap에 대해 공부하면서 제일 궁금했던 점이 왜 해시충돌할때 해결하는 방법이 2가지가 있으며,
왜 연결리스트말고도 트리구조도 있는지 이해가 안됬었는데 putVal메소드를 들여다보면서 궁금증이 많이 해소되었다.
왜 Hash자료구조에서 equals랑 hashCode를 같이 오버라이딩해야되는지 확실하게 이해할 수 있게 되어서 뿌듯한 시간이었다.
참고 블로그 :
https://velog.io/@ksyj8256/HashMap-%EB%9C%AF%EC%96%B4%EB%B3%B4%EA%B8%B0
https://woodcock.tistory.com/24
https://www.codelatte.io/courses/java_programming_basic/KW7N6AHSIJ00UUS4
'언어 > Java' 카테고리의 다른 글
| 왜 자바 직렬화는 Serializable 인터페이스가 있어야할까? (0) | 2024.01.30 |
|---|---|
| Executor, ExecutorService, Executors 동작원리 ( + ThreadPoolExecutor 디버깅) (1) | 2024.01.26 |
| [Java] String 덧셈 연산의 컴파일 최적화에 대해 알아보자 (0) | 2024.01.12 |
| Comparator로 보는 인터페이스와 정적 메서드 (1) | 2023.12.27 |
| 🐙 ArrayList는 내부적으로 어떻게 동작하며, 어떤 상황에서 사용하면 좋을까? (0) | 2023.12.26 |



