
개발자는 기록이 답이다
Executor, ExecutorService, Executors 동작원리 ( + ThreadPoolExecutor 디버깅) 본문
Executor, ExecutorService, Executors 동작원리 ( + ThreadPoolExecutor 디버깅)
slow-walker 2024. 1. 26. 02:34멀티 스레드에 대해 배우면서, 스레드를 재사용할 수 있는 스레드 풀에 대해 알게 되었다.
그런데 처음 보는 클래스와 인터페이스가 많아서 정리하면서 좀 더 확실히 이해하고자 한다.
여러 배경지식도 함께 포스팅했기 때문에 ThreadPoolExecutor의 디버깅 과정이 궁금하다면 하단에 있는 5번으로 가주시길 바랍니다.
1. 스레드 풀이란?
스레드 풀이 무엇인지 알기 전에 먼저 알아야 할 키워드는Thread Per Request Model 이다.
(One to one thread model이라고도 부른다. 이 부분은 오라클 문서를 참고하자)

이 방식은 웹 서버에서 요청이 들어올 때마다 새로운 스레드를 생성하여 해당 요청을 처리하므로, 각 요청은 독립적으로 실행되기 때문에 동시에 여러 요청을 처리할 수 있으므로 멀티 스레딩 방식이다.
하지만 이렇게 매번 요청이 올때마다 스레드를 생성하면 해당 스레드에 대한 운영체제 자원이 할당되므로 많은 비용이 든다.
다량의 요청이 들어오게 되고 병렬 처리 작업이 많아 질 수록 각 스레드는 CPU와 메모리를 계속 소비하면서 Out Of Memory가 발생하고, 스레드 생성과 소멸을 반복하면서 오버헤드가 발생하게 된다.
그렇다면 미리 스레드를 여러개 생성해놓고 재사용하는건 어떨까?
위의 단점을 보완하기 위해 나온 것이 바로 스레드풀(ThreadPool)이다.
병렬 작업의 갑작스러운 폭증을 막으려면 스레드 풀을 사용해야 한다.

스레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수 만큼 정해놓고 작업 큐(queue)에 들어오는 작업들을 하나씩 스레드가 맡아 처리한다. 작업 처리가 끝난 스레드는 다시 작업 큐에서 새로운 작업을 가져와 처리한다.
이렇게 스레드의 전체 개수를 제한해서 스레드 풀을 사용하면 작업 처리 요청이 폭증되어도 스레드의 전체 개수가 급증하지 않아서 애플리케이션의 성능이 급격히 저하되지 않는다.
Java5버전에서 이러한 스레드 풀을 기능이 추가되었고, 제공하는 java.util.concurrent패키지에 ExecutorService인터페이스와 Executors클래스를 제공하고 있다.

2. Executor 인터페이스
Executor인터페이스는 스레드풀(Thread Pool) 관리를 추상화한 인터페이스이다.
- "등록된 작업(Runnable)"을 실행하기 위한 인터페이스
- 작업 등록과 작업 실행 중에서 "작업 실행"만을 책임짐

등록된 작업(Runnable)을 실행하기 위한 인터페이스
여기서 조금 헷갈렸던게 Thread생성자도 인자로 Runnable을 받는걸로 알고 있는데,
Thread생성자랑 Executor인터페이스의 execute()메소드랑 다른게 무엇일지 궁금했다.
먼저 Thread 생성자 인자로 Runnable을 익명 클래스로 구현한 코드를 살펴보자
public class RunThreads {
public static void main(String[] args) {
RunThreads threads = new RunThreads();
threads.runBasic();
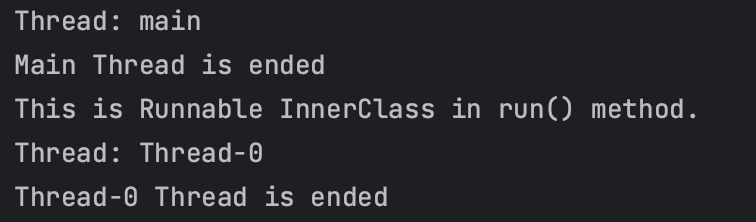
System.out.println("Thread: " + Thread.currentThread().getName());
System.out.println("Main Thread is ended");
}
private void runBasic() {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println("This is Runnable InnerClass in run() method.");
System.out.println("Thread: " + Thread.currentThread().getName());
System.out.println(Thread.currentThread().getName()+" Thread is ended");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
(위의 코드는 람다를 사용하면 더 간단한 코드 예시가 되겠지만, Runnable 객체를 사용한다는 것을 명시적으로 나타내기 위함이다)
그리고 Executor인터페이스의 execute()메소드를 구현한 코드를 살펴보자.
import java.util.concurrent.Executor;
public class RunExecutor implements Executor {
public static void main(String[] args) {
final Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Thread: " + Thread.currentThread().getName());
System.out.println(Thread.currentThread().getName()+" Thread is ended");
}
};
Executor executor = new RunExecutor();
executor.execute(runnable); // Executor를 구현한 클래스에서 execute()메소드 호출
}
@Override
public void execute(Runnable command) {
command.run();
}
}
[Main Thread]
|-> execute(runnable)
|-> command.run() [현재 스레드에서 실행]
위의 코드는 단순히 객체의 메소드를 호출하는 것이기 때문에, 새로운 스레드가 아닌 메인 스레드에서 실행된다.
새로운 스레드에서 실행하려면 Executor의 execute메소드를 아래와 같이 수정하면 된다.
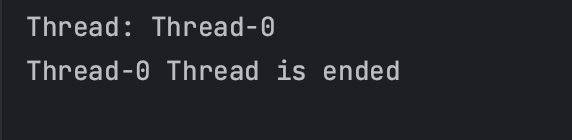
import java.util.concurrent.Executor;
public class RunExecutor implements Executor {
public static void main(String[] args) {
final Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Thread: " + Thread.currentThread().getName());
System.out.println(Thread.currentThread().getName()+" Thread is ended");
}
};
Executor executor = new RunExecutor();
executor.execute(runnable); // Executor를 구현한 객체에서 execute()메소드 호출
}
@Override
public void execute(Runnable command) {
new Thread(command).start(); // 새로운 스레드 생성
}
}
[Main Thread]
|-> execute(runnable)
|-> new Thread(command).start() [새로운 스레드 생성 및 시작]
|-> run() [새로운 스레드에서 실행]
여기서 그러면 new Thread()를 사용하는건 똑같은게 아닌가? 하고 의문을 가졌었다.
기본적으로 Runnable을 구현한 객체를 스레드로서 사용하려면 new Thread()의 인자로 넣어야 한다.
하지만 이러한 방식은 스레드를 직접 생성하고 관리하는 것으로, 아래와 같은 문제점이 있다.
- new Thread()를 사용하면 스레드 풀 없이 개별적인 새로운 스레드를 직접 생성하는 것이다.
- 작업이 완료되면 스레드가 종료되므로 재사용할 수가 없다.
- 위에서 언급했던 Thread per Request Model로 매번 스레드를 생성하고 종료하므로 오버헤드가 발생한다.
- 개발자가 직접 스레드를 관리해야 하며, 부가적인 작업이 필요하다
반면에 Executor인터페이스의 execute()메소드를 사용하면 아래와 같은 특징이 있다.
- 백그라운드에서 관리되는 스레드 풀을 통해 스레드의 수를 제한하고, 작업을 처리한다.
- 작업이 완료되면 해당 스레드는 풀에 반환되어 재사용하므로 스레드 생성과 종료에 대한 비용이 감소한다.
- 작업 큐를 통해 들어온 작업이 스레드에 할당되어 순차적으로 처리되며, 스레드 풀에서 놀고 있는 스레드가 해당 작업을 처리한다.
- 스레드 생성, 종료, 예외 처리등 내부적으로 관리해서 개발자가 따로 신경쓸 필요가 없다.
여기서 중요한 차이점은 스레드 풀을 사용한다는 것이다. 추가적으로 Executor은 스레드풀을 사용하기 위한 추상화 단계일 뿐이다.
스레드 풀은 작업 큐를 사용하여 작업을 관리하는데, execute만 호출했다고 해서 작업이 즉시 실행되는 것은 아니다. 작업은 큐에 등록되고 스레드 풀 내부에서 적절한 시점에 실행되고, execute메소드는 "등록된 작업을 실행"할 뿐이다.
작업 등록과 작업 실행 중에서 "작업 실행"만을 책임짐
스레드 작업은 크게 2가지로 나뉘어 진다.
- 작업의 등록
- 작업의 실행
그 중에서도 Executor 인터페이스는 인터페이스 분리 원칙(Interface Segregation Principle)에 맞게 등록된 작업을 실행하는 책임만 갖는다. 그래서 전달받은 작업(Runnable)을 실행하는 메소드만 가지고 있다.
다시 문서를 봐도, 해당 메소드는 미래의 어떤 시점에 "실행"하고, 새로운 스레드를 생성하거나, 기존의 스레드를 재사용하거나, 호출 스레드에서 직접 실행하는 등 실행 방식이 Executor 구현의 재량에 따라 달라질 수 있다고 나와있다.

이제 추상화의 맨 첫 단계를 봤으니 다음으로 ExecutorService 인터페이스를 살펴보자
3. ExecutorService 인터페이스
ExecutorService는 작업(Runnable, Callable) 등록을 위한 인터페이스이다. ExecutorService는 Executor를 상속받아서 작업 등록 뿐만 아니라 실행을 위한 책임도 갖는다. 그래서 스레드 풀은 기본적으로 ExecutorService 인터페이스를 구현한다. 대표적으로 ThreadPoolExecutor가 ExecutorService의 구현체인데, ThreadPoolExecutor 내부에 있는 블로킹 큐에 작업들을 등록해둔다.
(여기서 말하는 블로킹 큐가 작업 큐를 의미한다)
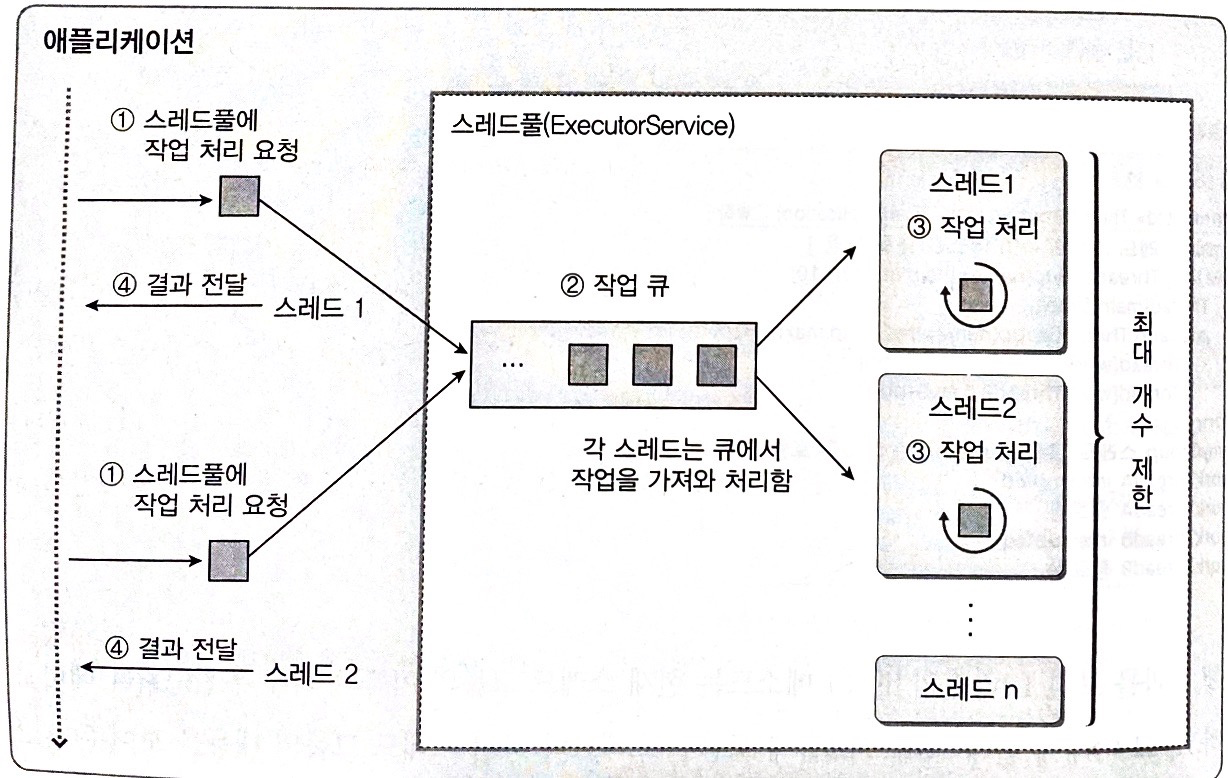
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
각 스레드는 작업들을 할당받아 처리하는데, 만약 사용가능한 스레드가 없다면 작업은 큐에 대기하게 된다. 그러다가 스레드가 작업을 끝내면 다음 작업을 할당받게 되는 것이다. 이러한 ExecutorService가 제공하는 퍼블릭 메소드들은 다음과 같이 분류 가능하다.
- 라이프사이클 확인 및 관리 (스레드 종료)
- 비동기 작업을 위한 기능들
우선 각 기능들을 테스트해보기 전에 알아야 할 클래스가 또 하나 있다. 바로 Executors 클래스이다.
4. Executors 클래스
Executors는 ExecutorService 인터페이스를 구현한 여러 유형의 스레드 풀을 생성할 수 있는 팩토리 클래스이다.
특히, ThreadPoolExecutor 클래스를 사용하여 스레드 풀을 만들 수 있다. Executors는 간단한 팩토리 메서드를 제공하여 일반적인 구성 설정으로 스레드 풀을 만들 수 있도록 도와준다. 다만, Executors를 사용하면 편의성과 간단한 사용을 제공하지만, 상세한 설정이나 제어가 필요한 경우에는 직접 ThreadPoolExecutor를 구성하는 것이 더 적절할하다.
스레드 풀 관련해서 찾아보면 보통 아래 2개의 메소드로 스레드풀을 생성 예제 코드를 볼 수 있다.

| 메소드명(매개변수) | 초기 스레드 수 | 코어 스레드 수 | 최대 스레드 수 |
| newCachedThreadPool() | 0 | 0 | Integer.MAX_VALUE |
| newFixedThreadPool(int nThreads) | 0 | nThreads | nThreads |
- 초기 스레드 수 : ExecutorService 객체가 생성될 때 기본적으로 생성되는 스레드 수
- 코어 스레드 수 : 스레드 수가 증가된 후 사용되지 않는 스레드를 스레드 풀에서 제거할 때 최소한 유지해야 할 스레드 수
- 최대 스레드 수 : 스레드 풀에서 관리하는 최대 스레드 수
newCachedThreadPool()
스레드 개수보다 작업 개수가 많으면 스레드를 생성시켜 작업을 처리한다.
이론적으로 Int값이 가질 수 있는 최대값(21억 정도)만큼 스레드가 추가되지만, 운영체제의 성능과 상황에 따라 달라진다.
1개 이상의 스레드가 추가되었을 경우 60초 동안 추가된 스레드가 아무 작업을 하지 않으면 추가된 스레드를 종료하고 풀에서 제거한다.
ExecutorService executorService = Executors.newCachedThreadPool();
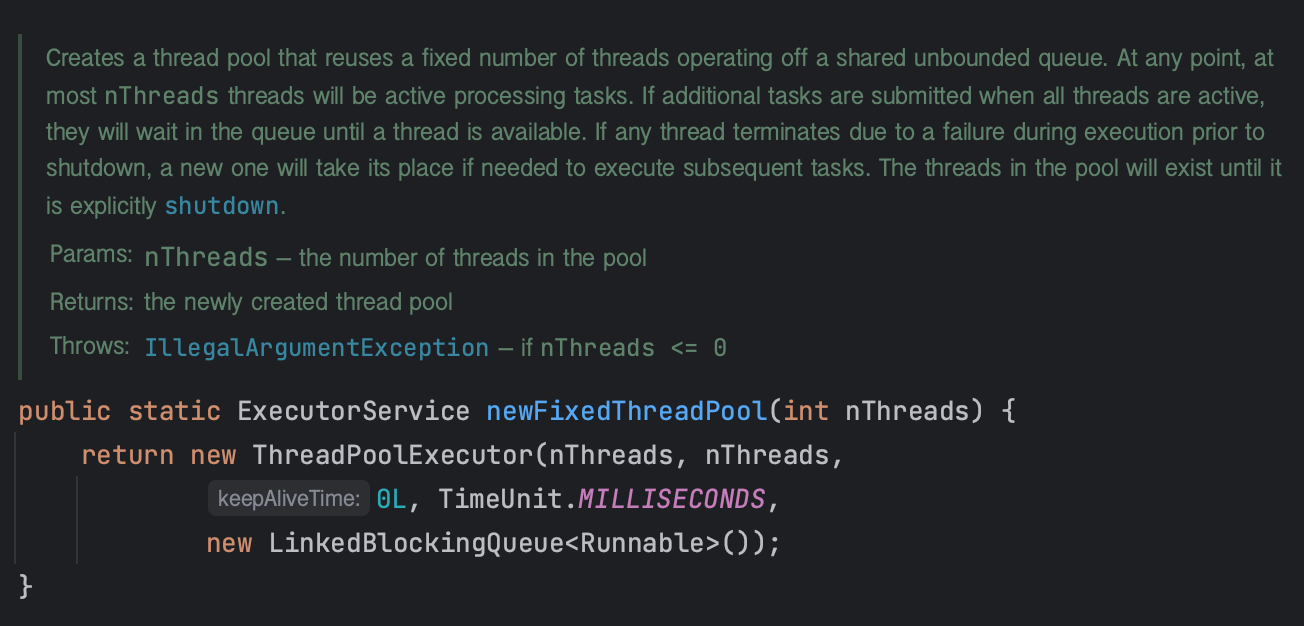
newFixedThreadPool(int nThreads)
스레드 개수보다 작업 개수가 많으면 새 스레드를 생성시키고 작업을 처리한다.
최대 스래드 개수는 매개값으로 준 nThreads이다. 이 스레드 풀은 스레드가 작업을 처리하지 않고 놀더라도 스레드 개수가 줄지 않는다.
보통 아래 코드처럼 CPU 코어의 수만큼 최대 스레드를 사용하는 스레드풀을 생성한다.
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
하지만 이 메소드 2개는 설명에서 알 수 있듯이 단점이 존재한다.
newCachedThreadPool() 메소드의 경우 동적으로 스레드를 관리하지만, 최대 스레드 수가 int의 최대값까지 가질 수 있으므로 스레드가 폭증할 가능성이 있다.
newFixedThreadPool() 메소드의 경우 코어 스레드 수와 최대 스레드 수가 같아서, 스레드가 유휴시간을 보내도 스레드 수가 줄지 않으므로 불필요한 스레드를 오랫동안 유지하면서 자원을 낭비 할 수 있다.
따라서 해당 메소드들을 사용하기보다 ThreadPoolExecutor객체를 사용하는게 더 효율적이다. 사실 위에 있는 2개 메소드들도 사진상으로보면 내부적으로 ThreadPoolExecutor 객체를 생성해서 반환하는 것을 알 수 있다.
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
3, // 코어 스레드 수
100, // 최대 스레드 개수
120L, // 놀고 있는 시간
TimeUnit.SECONDS, // 놀고 있는 시간 단위
new SynchronousQueue<Runnable>() // 작업 큐
);
ThreadPoolExecutor에 대해서는 아래서 더 설명할 예정이니, ExecutorService인터페이스의 메소드로 돌아가보자.
3-1. ExecutorService 의 기능들
4에서 다시 3-1로 왔다고 너무 혼동하지 말자.
3번에 있던 ExecutorService인터페이스에 있던 메소드들을 다시 한번 보기 위함이다.
해당 메소드들을 실행하기 위해서는 스레드 풀을 생성해야 하는데, 그때 Executors의 팩토리 메서드를 사용하기 때문에 미리 언급했던 것이다.
라이프사이클 확인 및 관리 (스레드 종료)
스레드풀의 스레드는 기본적으로 데몬 스레드가 아니기 때문에, main스레드가 종료되더라도 작업을 처리하기 위해 계속 실행 상태로 남아있다. 그래서 main() 메소드가 실행이 끝나더라도 애플리케이션 프로세스는 종료되지 않는다.
따라서 애플리케이션을 종료하려면 스레드풀을 종료시켜 스레드들이 종료상태가 되도록 처리해야 한다.
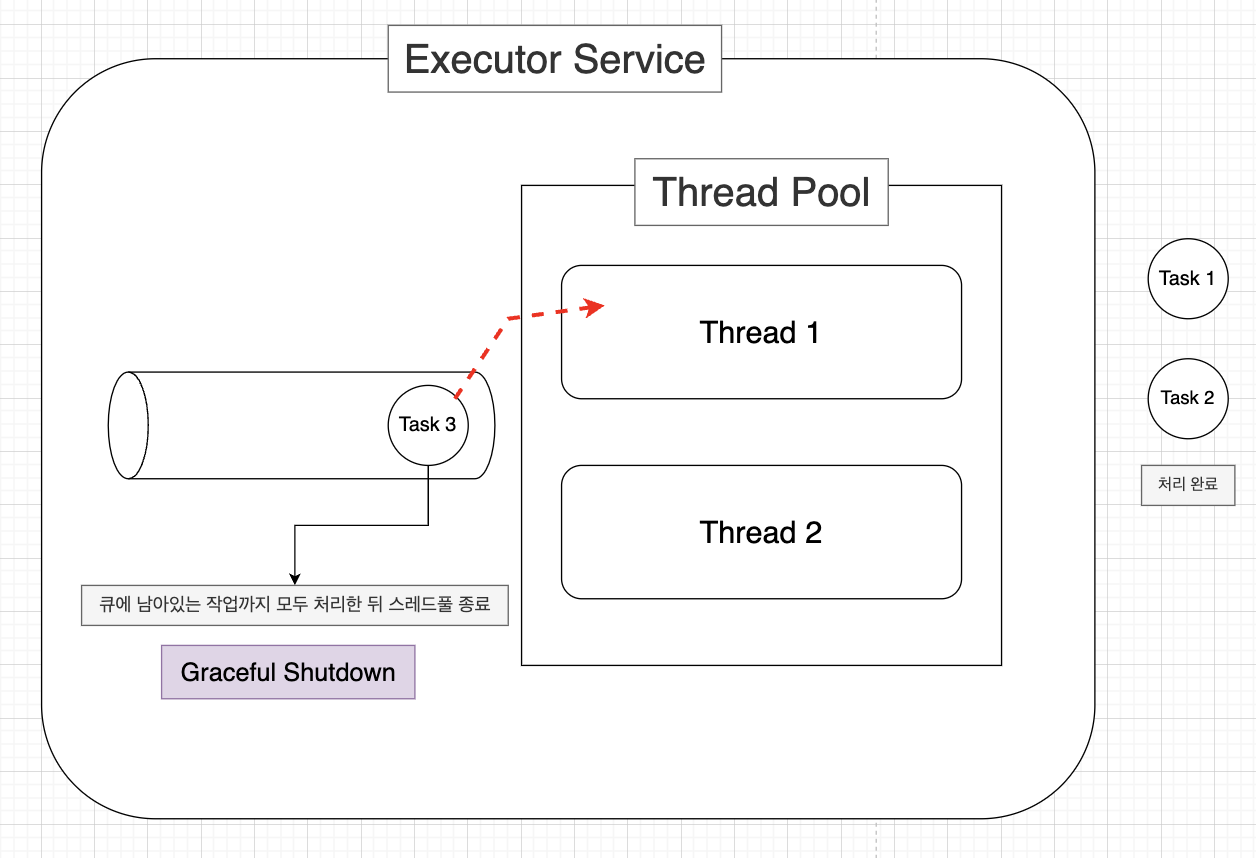
- void shutdown();
- 새로운 작업들을 더 이상 받아들이지 않음
- 제출된 작업들이랑 대기중이던 작업들까지 모두 처리 완료되고나서 스레드 풀이 종료됨(Graceful Shutdown)


import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
public class ThreadLifeCycle {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = (ThreadPoolExecutor)Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
int poolSize = threadPoolExecutor.getPoolSize();
String threadName = Thread.currentThread().getName();
System.out.println("[총 스레드 개수: "+ poolSize + "] 작업 스레드 이름: " + threadName);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
};
executor.execute(runnable);
}
// shutdown 호출
executor.shutdown();
}
}
- List<Runnable> shutdownNow();
- shutdown 기능에 더해 이미 제출되어 처리중인 작업들을 인터럽트시킴
- 실행을 위해 대기중인 작업 목록(List<Runnable>)을 반환함
- 처리 중이던 작업들이 중간에 중지되면서 불완전하게 작업이 끝날 수 있기 때문에 가급적이면 사용하지 않는게 좋다.

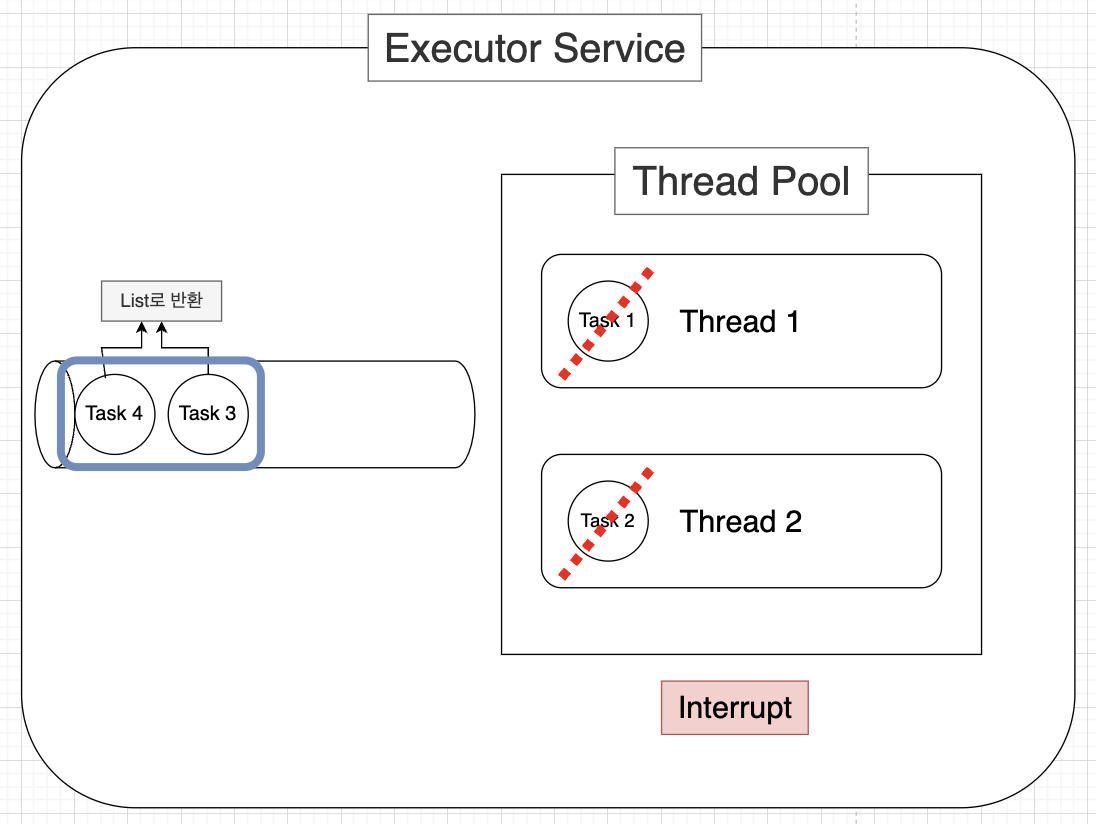
- boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
- shutdown이 Graceful Shutdown이긴 하지만, 언제까지 남은 작업을 처리할때 까지 기다릴 수 없을때 사용
- shutdown 실행 후, 지정한 시간(timeout) 동안 모든 작업이 종료될 때 까지 대기함
- 지정한 시간 내에 모든 작업 완료하면 true, 완료하지 못하면 interrput하고 false 반환
- boolean isShutdown();
- Executor의 shutdown 여부를 반환함
- boolean isTerminated();
- shutdown 실행 후 모든 작업의 종료 여부를 반환함
ExecutorService를 만들어 작업을 처리하면 shutdown이 호출되기 전까지 계속 다음 작업을 대기하게 된다.
그러므로 작업이 완료되었다면 반드시 shutdown을 명시적으로 호출해줘야 한다. shutdown을 호출할 경우 스레드 풀에 새로운 작업 받아들일 수 없다.
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadLifeCycle {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("Thread: " + Thread.currentThread().getName());
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
};
executorService.execute(runnable);
// shutdown 호출
executorService.shutdown();
// 새로운 작업 제출 시 RejectedExecutionException 에러 발생
executorService.execute(runnable);
}
}Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task lang.thegodofjava.Chapter25.study.ThreadLifeCycle$1@2a84aee7 rejected from java.util.concurrent.ThreadPoolExecutor@a09ee92[Shutting down, pool size = 1, active threads = 1, queued tasks = 0, completed tasks = 0]
at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2065)
at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:833)
at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1365)
at lang.thegodofjava.Chapter25.study.ThreadLifeCycle.main(ThreadLifeCycle.java:26)
Thread: pool-1-thread-1
아래 예시는 지금까지 배운 기능들로 실제로 shutdown이 큐에서 대기중인 작업들까지 전부 처리 완료하고 종료되는지 확인하는 코드이다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadLifeCycle {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = (ThreadPoolExecutor)Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
int poolSize = threadPoolExecutor.getPoolSize();
int activeThreads = threadPoolExecutor.getActiveCount();
int queuedTasks = threadPoolExecutor.getQueue().size();
long completedTasks = threadPoolExecutor.getCompletedTaskCount();
String threadName = Thread.currentThread().getName();
Thread.sleep(1000);
System.out.println("[총 스레드 개수: "+ poolSize + "] 작업 스레드 이름: " + threadName);
System.out.println("[활성 상태인 스레드 개수: " + activeThreads +", 대기 중인 작업의 큐 개수: " + queuedTasks + ", 처리 완료된 작업의 수: "+completedTasks +" ]");
} catch (InterruptedException e) {
e.printStackTrace();
}
};
};
executor.execute(runnable);
}
// shutdown 호출
executor.shutdown();
// 스레드 풀이 종료될 때까지 대기 (최대 1시간까지 대기)
executor.awaitTermination(1, TimeUnit.HOURS);
// 모든 작업이 완료된 이후에 Completed tasks 확인
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
long completedTasks = threadPoolExecutor.getCompletedTaskCount();
System.out.println("전체 처리 완료된 작업의 수: " + completedTasks);
}
}
비동기 작업을 위한 기능들 (+ 블로킹 방식)
ExecutorService는 Runnable과 Callbale을 작업으로 사용하기 위한 메소드를 제공한다. 동시에 여러 작업들을 실행시키는 메소드도 제공하고 있는데, 비동기 작업의 진행을 추적할 수 있도록 Future를 반환한다. 반환된 Future들은 모두 실행된 것이므로 반환된 isDone은 true이다. 하지만 작업들은 정상적으로 종료되었을 수도 있고, 예외에 의해 종료되었을 수도 있으므로 항상 성공한 것은 아니다. 이러한 ExecutorService가 갖는 비동기 작업을 위한 메소드들을 정리하면 다음과 같다.
- submit
- 실행할 작업들을 큐에 추가하고, 지연완료(penging completion)객체인 Future를 반환함
- 작업이 완료될때까지 기다렸다가 최종 결과를 얻기 위해 get()메소드 호출
- 리턴값이 없는 Runnable객체를 submit할 경우, get()메소드로 결과값이 null이 나온다.
- 결과값을 얻을 필요가 없는 경우 이므로 단지 스레드가 작업을 완료할때 까지 기다리는 블로킹 상태가 된다.
- 실행할 작업들을 큐에 추가하고, 지연완료(penging completion)객체인 Future를 반환함
- invokeAll
- 모든 결과가 나올 때 까지 대기하는 블로킹 방식의 요청
- 동시에 주어진 작업들을 모두 실행하고, 전부 끝나면 각각의 상태와 결과를 갖는 List<Future>을 반환함
- invokeAny
- 가장 빨리 실행된 결과가 나올 때 까지 대기하는 블로킹 방식의 요청
- 동시에 주어진 작업들을 모두 실행하고, 가장 빨리 완료된 하나의 결과를 Future로 반환받음
( 다른 블로그에서 가져온 내용인데 이부분은 자세히 모르겠다...블로킹인데 비동기라니 ...추후에 다시 업데이트 해야겠다)
5. ThreadPoolExecutor
이제 위에서 언급했었던 ThreadPoolExecutor의 동작원리에 대해 알아보고자 한다.
객체 생성하고 execute메소드 실행하면서 어떻게 동작되는지 디버깅해보자.
코어 스레드 개수는 2개, 최대 스레드 개수는 3개이다.
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorExample {
public static void main(String[] args) throws InterruptedException {
// ThreadPoolExecutor 생성
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // Core Pool Size
3, // Maximum Pool Size
0L, // Keep Alive Time
TimeUnit.MILLISECONDS, // Time Unit for Keep Alive
new LinkedBlockingQueue<>() // Work Queue
);
// 작업 생성 및 제출
for (int i = 0; i < 5; i++) {
final int taskId = i;
executor.execute(() -> {
try {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(2); // 일부러 작업 시간을 늘림
System.out.println("Task " + taskId + " is completed");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 스레드 풀 정보 출력
printThreadPoolInfo(executor);
// 스레드 풀 종료
executor.shutdown();
// 스레드 풀이 종료될 때까지 대기
executor.awaitTermination(10, TimeUnit.SECONDS);
// 스레드 풀 종료 후 정보 출력
printThreadPoolInfo(executor);
}
private static void printThreadPoolInfo(ThreadPoolExecutor executor) {
System.out.println("Core Pool Size: " + executor.getCorePoolSize());
System.out.println("Active Threads: " + executor.getActiveCount());
System.out.println("Queued Tasks: " + executor.getQueue().size());
System.out.println("Completed Tasks: " + executor.getCompletedTaskCount());
System.out.println("Task Count: " + executor.getTaskCount());
System.out.println("Pool Size: " + executor.getPoolSize());
System.out.println("Largest Pool Size: " + executor.getLargestPoolSize());
System.out.println("===============================");
}
}
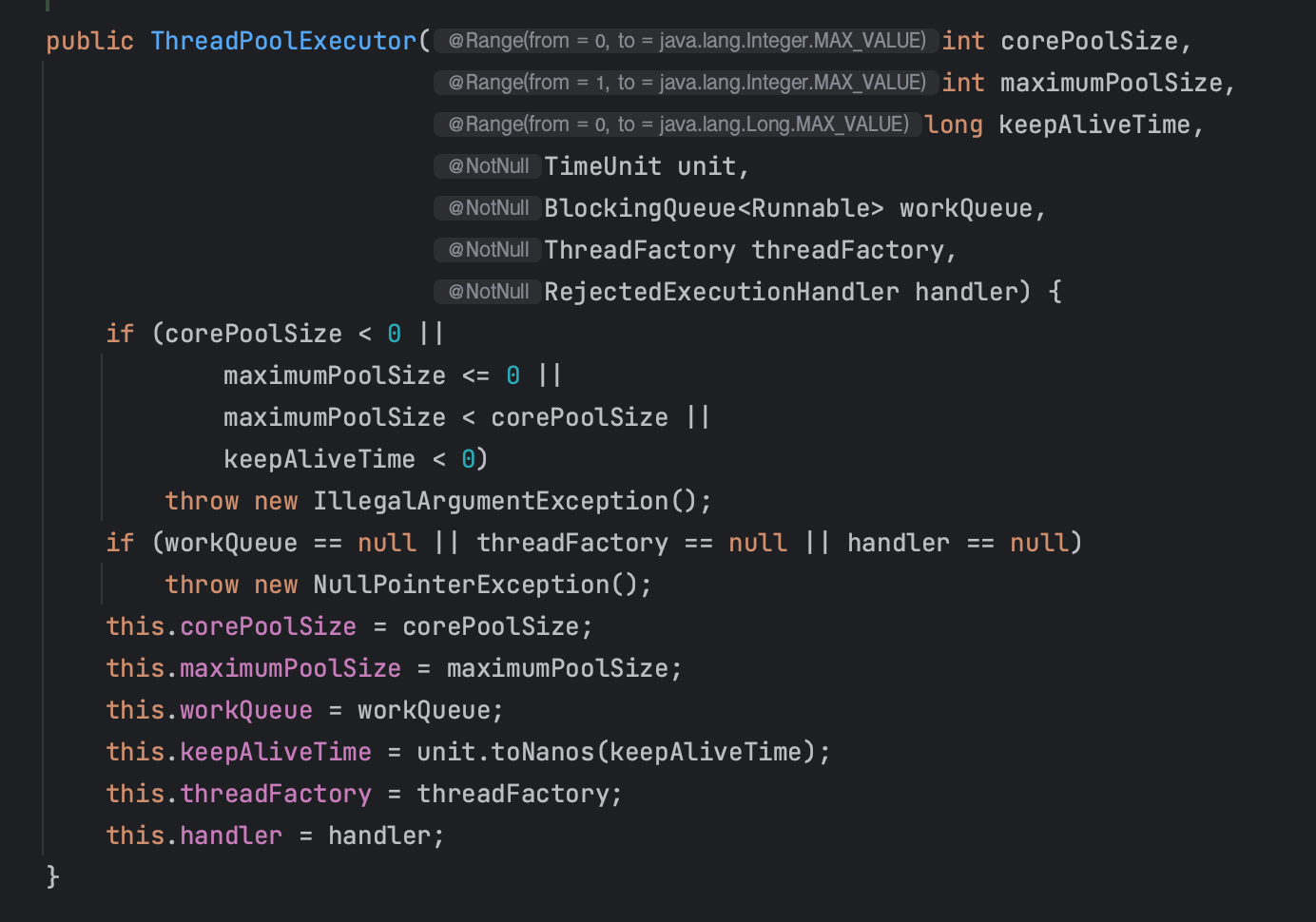
먼저 ThreadPoolExecutor의 생성자는 총 4가지가 있다.
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory)
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
공통적인 부분은 위에서 이미 ExecutorService의 구현체들을 보면서 매개변수의 내용이 익숙하겠지만 다시 한번 정리해보자.
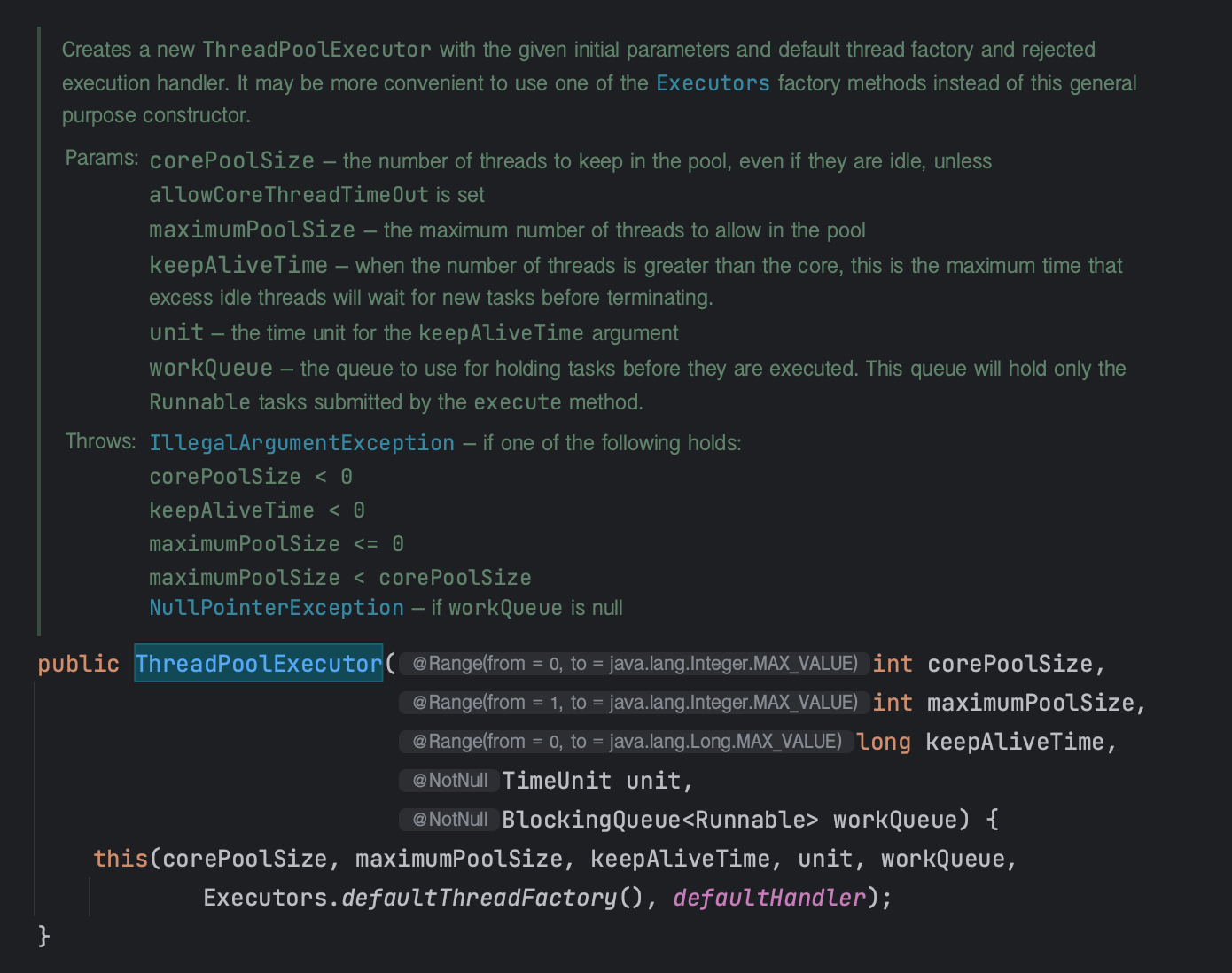
- corePoolSize : 스레드 풀에 유지할 최소 스레드 수
- maximumPoolSize : 스레드 풀에서 허용되는 최대 스레드 수
- KeepAliveTime : 코어 스레드 이상의 스레드 수가 존재하고 유휴 상태인 경우, 이 시간동안 작업이 제공되길 기다리다가 시간이 경과해도 새로운 작업이 할당되지 않으면 대기 중이던 스레드가 종료된다
- unit : KeepAliveTime의 시간 단위
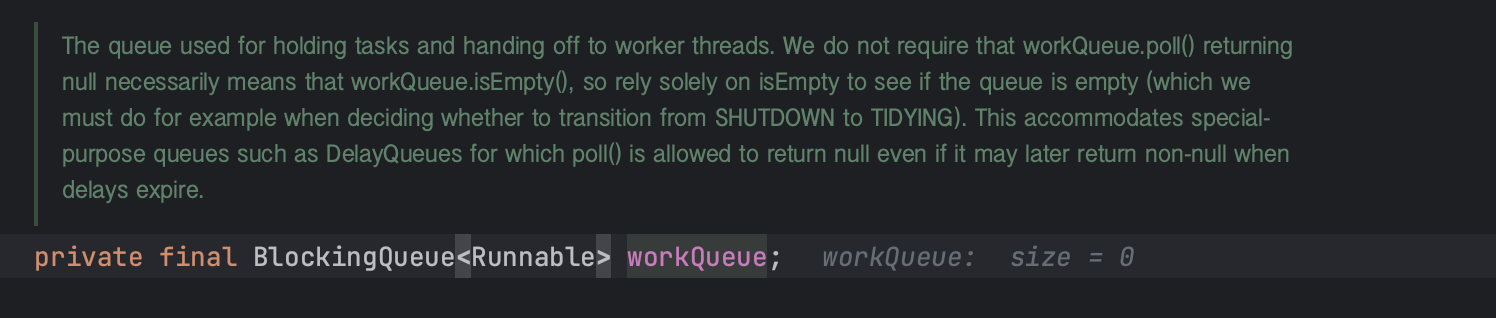
- workQueue : 작업이 실행되기 전에 보관되는 큐
생성자 내부에 this()로 다른 생성자를 호출하며서 RejectedExecutionHandler와 ThreadFactory를 내부적으로 설정하는 것을 알 수 있다.
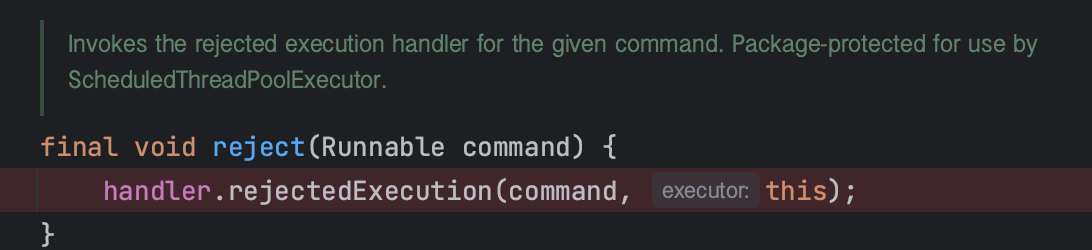
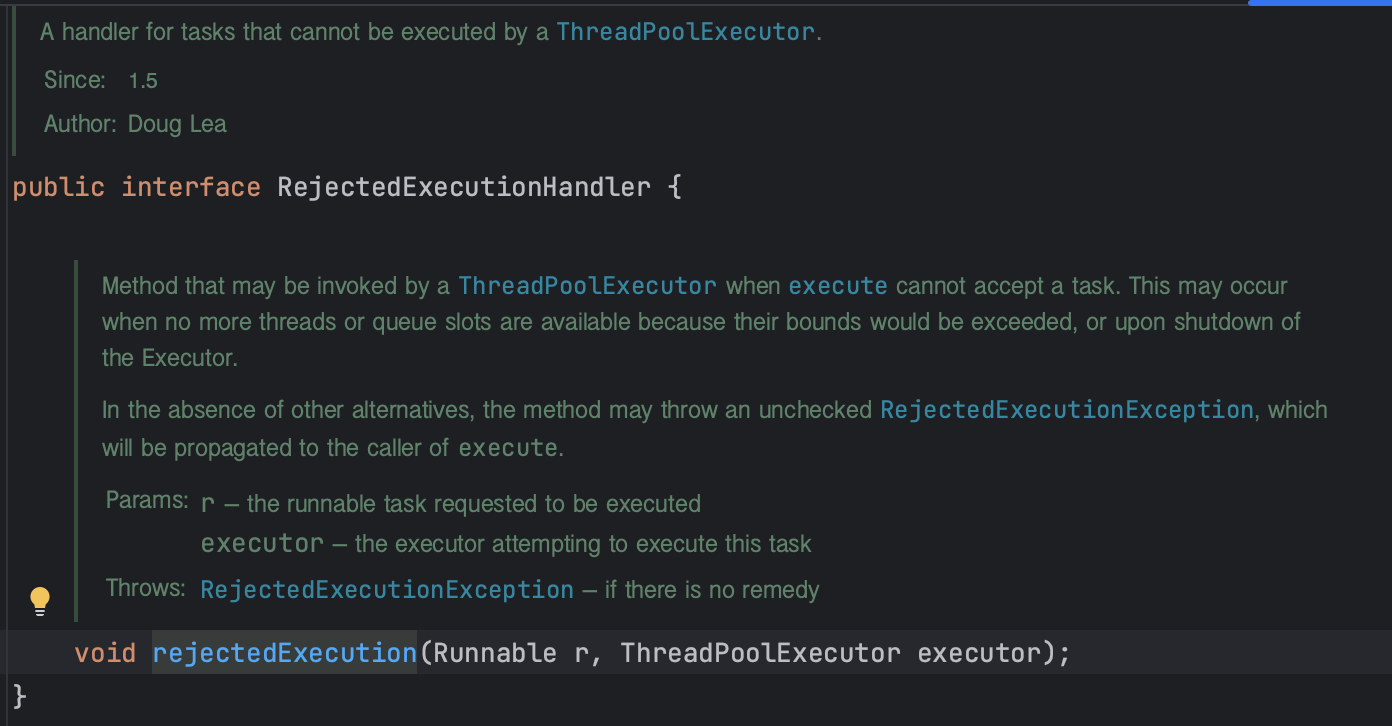
- RejectedExecutionHandler: 작업이 풀에 추가될 수 없을 때 호출되는 핸들러.
- 3-1에서 shutdown메소드 호출 후 다시 execute를 호출할때 발생했던 RejectedExecutionException이다.

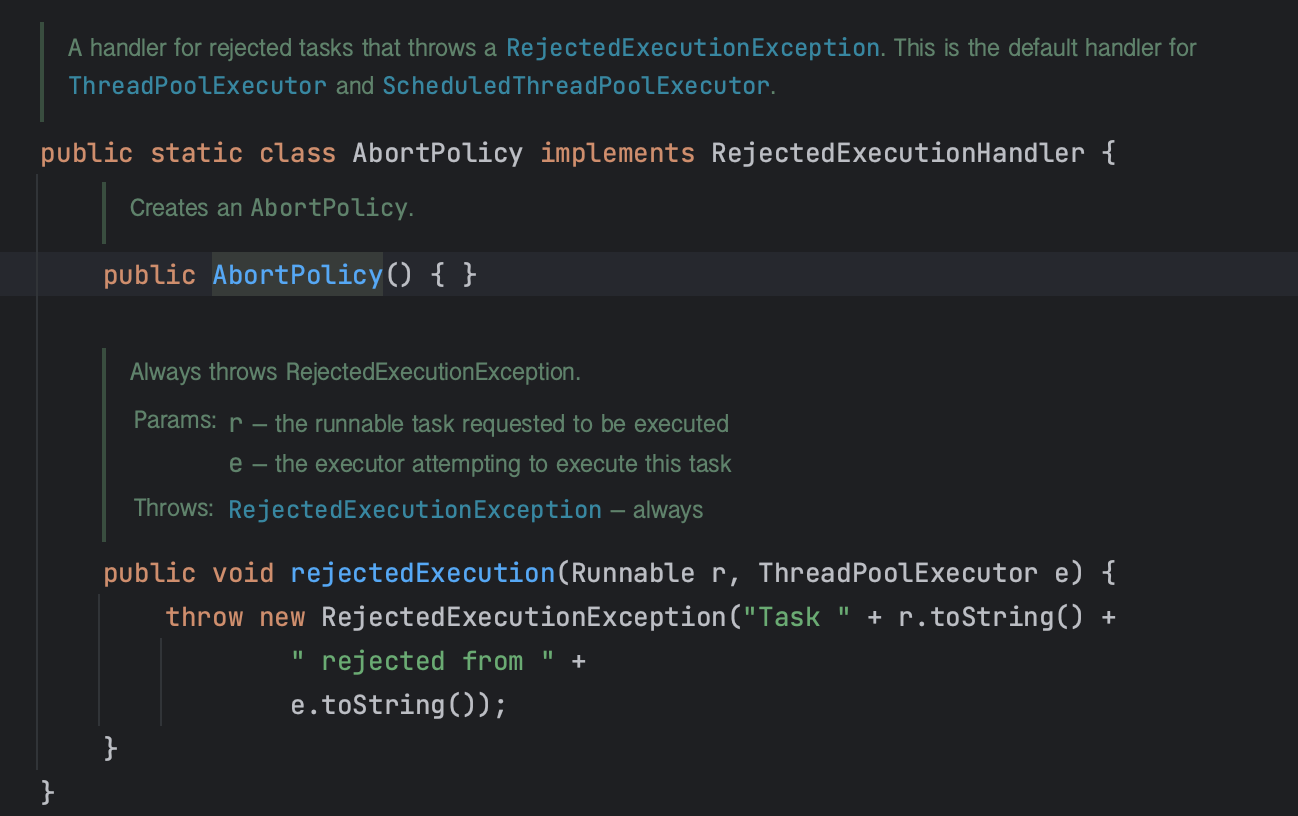
- ThreadFactory: 새로운 스레드를 생성하는 데 사용되는 팩토리
- Executors의 내부 static메소드에서 DefaultThreadFactory 객체를 생성하고 있다.
- DefaultThreadFactory는 ThreadFactory인터페이스의 구현체로, 스레드 풀 내에서 스레드를 생성하는 역할을 한다.

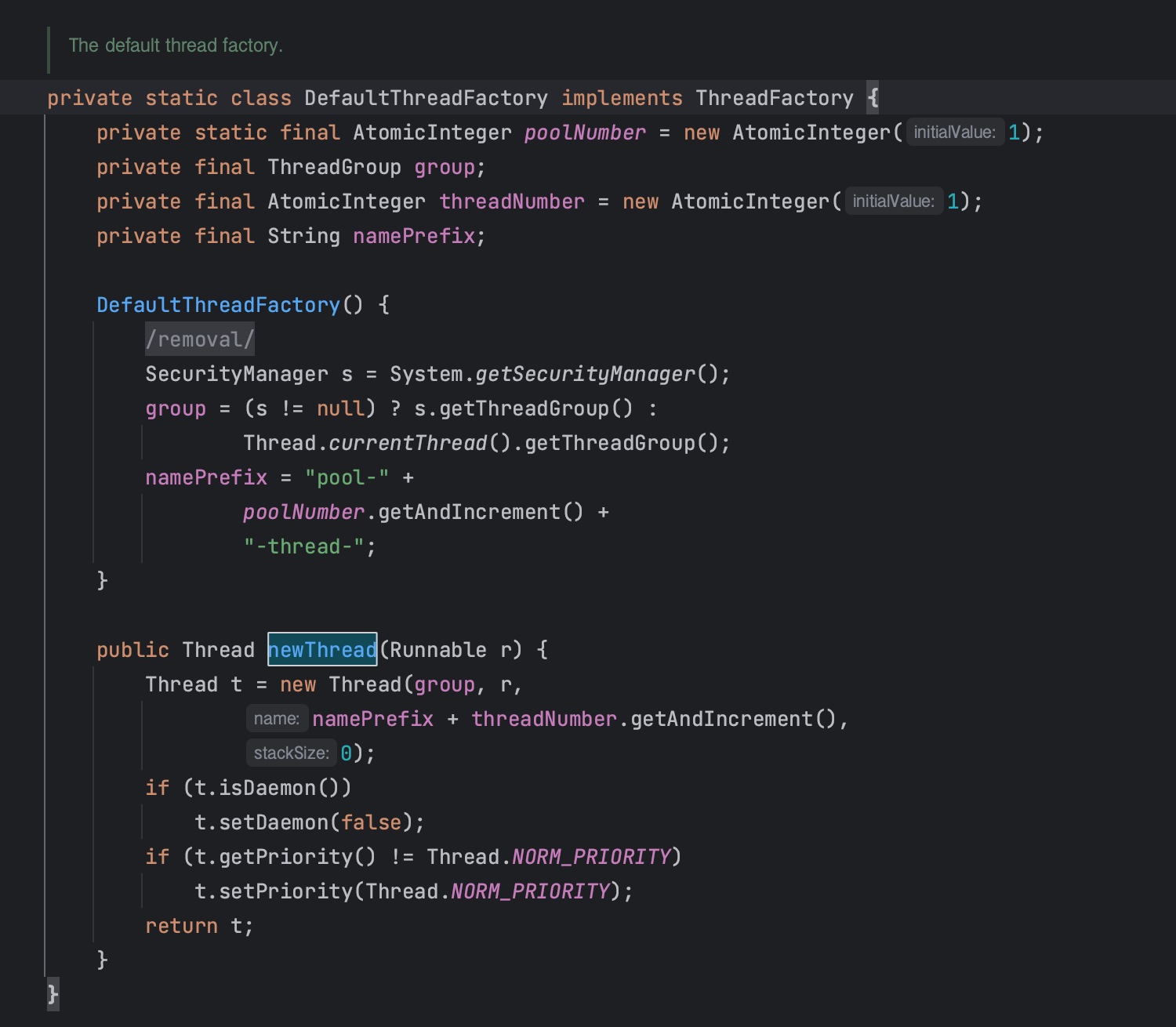
- poolNumber: 스레드 풀의 번호를 나타내는 정수
- group: 스레드를 생성할 때 사용할 ThreadGroup
- threadNumber: 생성된 스레드의 번호를 나타내는 정수
- namePrefix: 스레드의 이름을 결정하는 프리픽스
- 지금까지 출력값으로 봐왔던 "pool-1-thread2" 가 바로 이것이다.
이것 외에 this()로 내부에 있는 다른 생성자 호출하는 건 간단하다.
이제 객체를 생성했으니 execute 메소드를 호출해서 어떻게 동작하는지 살펴보자.
execute의 구조는 크게 3가지로 나뉘어 진다.
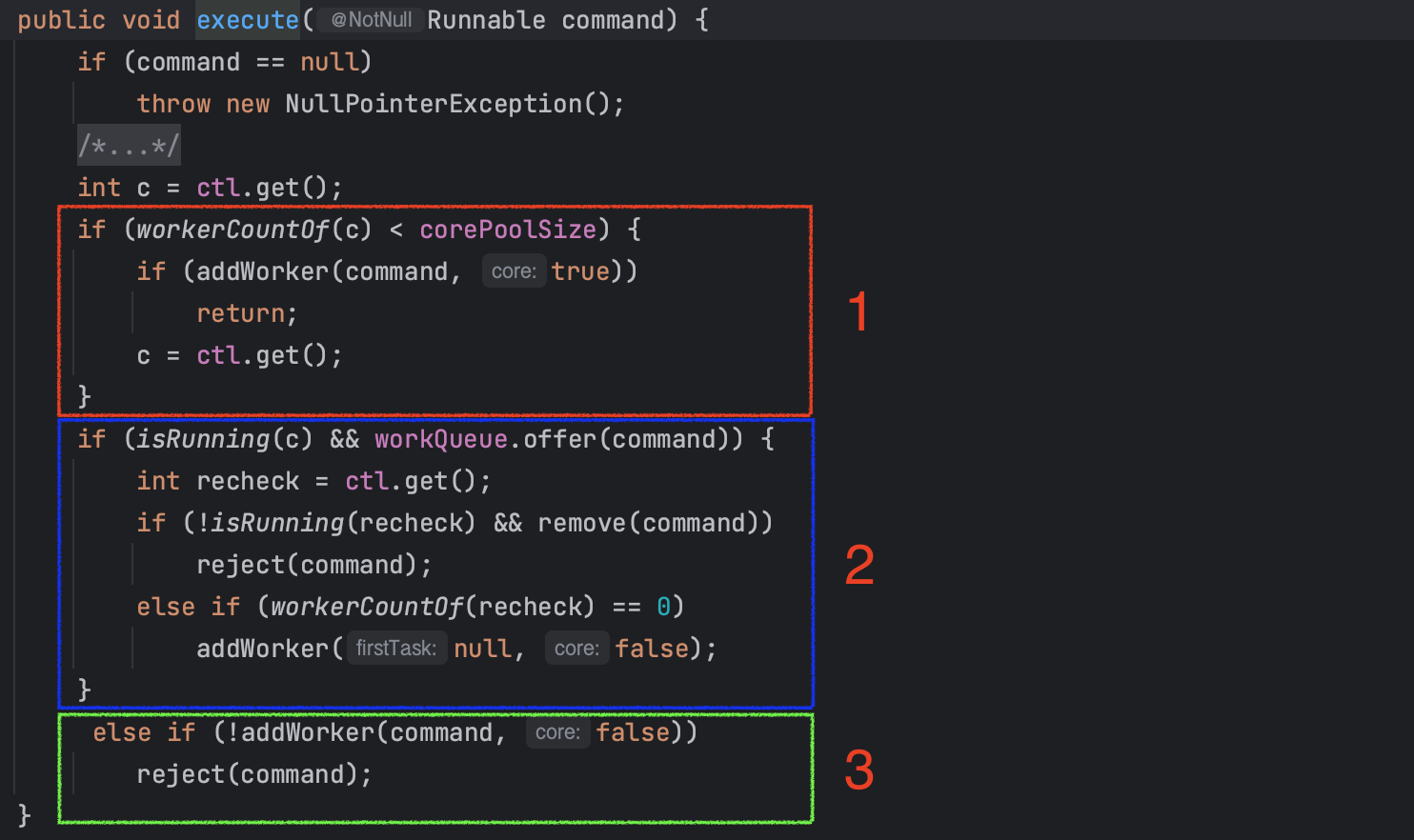
(1) 새로운 워커 스레드 추가
- 현재 동작 중인 코어 스레드 수가 corePoolSize보다 작을때 새로운 워커 스레드를 추가한다
(2) 작업 큐에 작업을 제공하고 추가적인 동작을 수행
- 스레드 풀이 실행중이고, 작업 큐에 작업을 성공적으로 등록했을때 진행한다
- 만약 스레드 풀이 실행 중이 아니거나, 작업 큐에 작업을 제공하던 중에 스레드 풀이 종료되었다면 작업을 제거하고 예외처리한다
- 워커 스레드가 없는 경우 새로운 스레드를 추가한다
(3) 작업을 큐에 제공할 수 없는 경우 작업을 거부
- 작업을 큐에 등록할 수 없는 경우(큐가 가득 찼거나, 스레드를 추가할 수 없는 경우) 작업을 거부한다
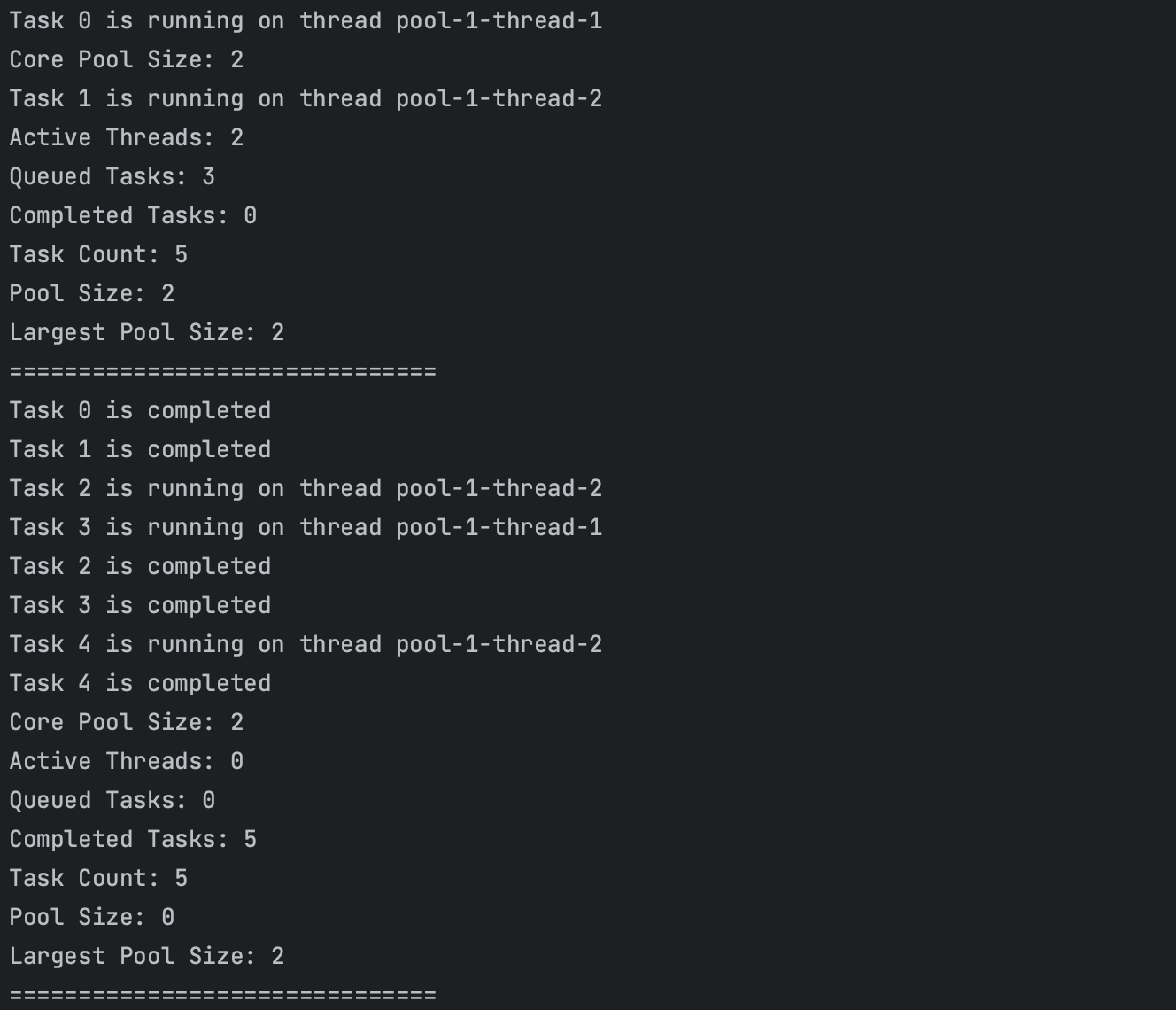
5개의 작업을 등록하고 실행하는 디버깅 부분이다.
// 작업 생성 및 제출
for (int i = 0; i < 5; i++) {
final int taskId = i;
executor.execute(() -> {
try {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(2); // 일부러 작업 시간을 늘림
System.out.println("Task " + taskId + " is completed");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
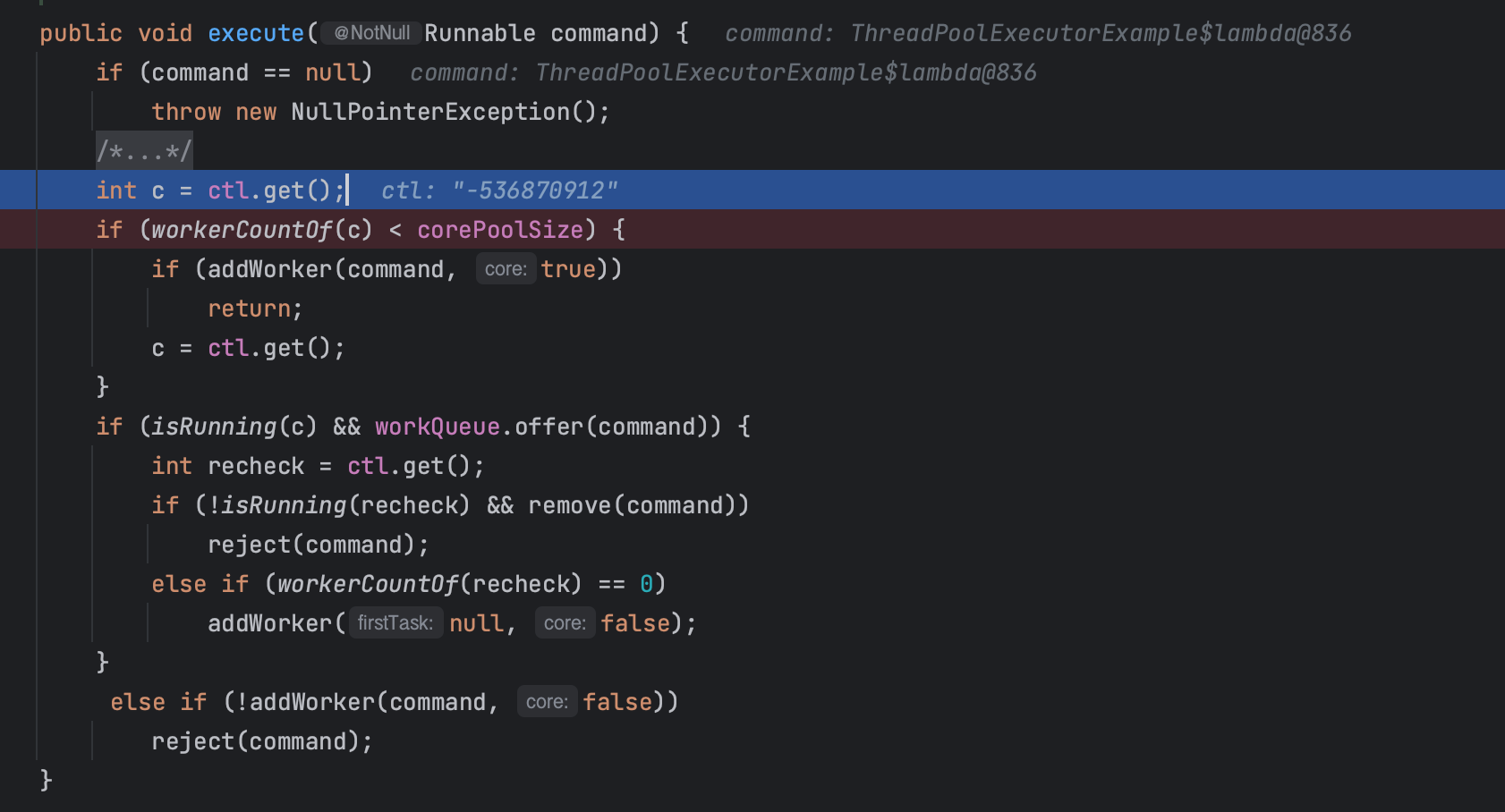
우선 현재 스레드 풀의 제어 상태를 가져와서 c 변수에 할당한다.
int c = ctl.get();
여기서 ctl이라는 것은 스레드 풀의 상태를 담는 AtomicInteger 변수이고 ctlOf() 메소드를 호출한다.
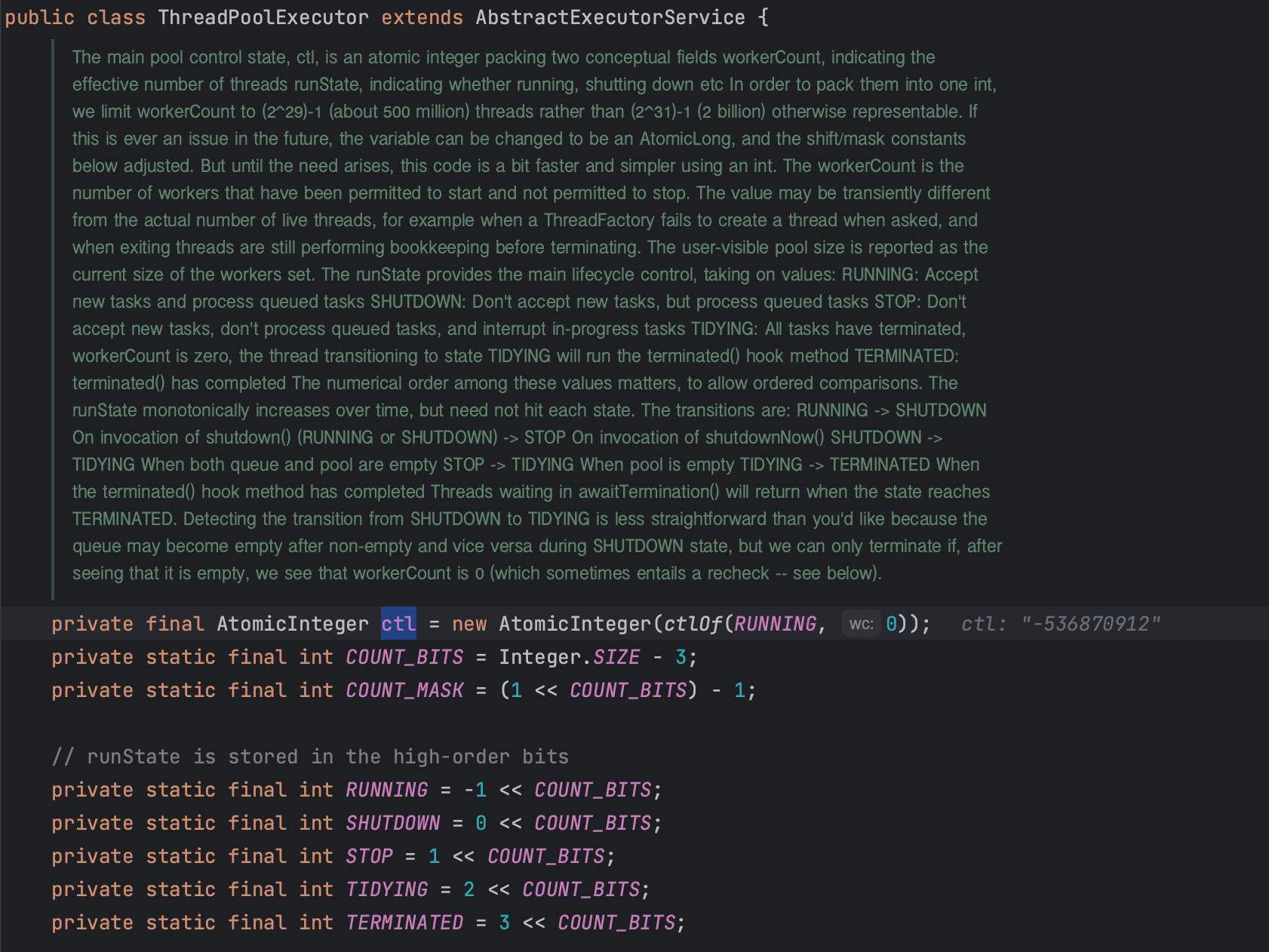
ctlOf() 메소드는 ThreadPoolExecutor의 컨트롤러 상태(ctl)를 생성하기 위한 메소드이다.
- rs : runState - 주어진 상태
- RUNNING (0x00000000): 스레드 풀이 활성 상태이며 작업을 처리할 수 있는 상태
- SHUTDOWN (0x01000000): 스레드 풀이 종료 중이며 작업을 처리하지 않는 상태 (큐에 남아있는 작업은 계속 처리)
- STOP (0x02000000): 스레드 풀이 종료 중이며 작업을 처리하지 않는 상태 (큐에 남아있는 작업도 중지)
- TIDYING (0x03000000): 종료 작업이 진행 중이며 모든 작업자 스레드가 종료되었음을 나타냄
- TERMINATED (0x04000000): 종료 상태이며 모든 종료 작업이 완료되었음을 나타냄
- wc : workCount - 실행중인 스레드 수

이렇게 상태와 실행 중인 스레드 수를 합쳐서 하나의 정수로 만들면, AtomicInteger를 사용하여 ctl 변수를 원자적으로 갱신할 때 경쟁 조건(Race condition)을 피할 수 있다.
ctlOf(RUNNING, 0)은 RUNNING 상태이며 실행 중인 스레드가 0개라는 것을 의미한다.
즉, 스레드 풀이 실행 중이지만 현재 실행 중인 스레드는 없다( 아무 작업도 수행 중이지 않다 )
ctl의 값을 할당한 c 변수("-536870912")를 통해 1번 조건문으로 오면, workerCountOf() 메소드를 통해 실행 중인 스레드 수를 추출해서 코어 스레드 수와 비교한다.
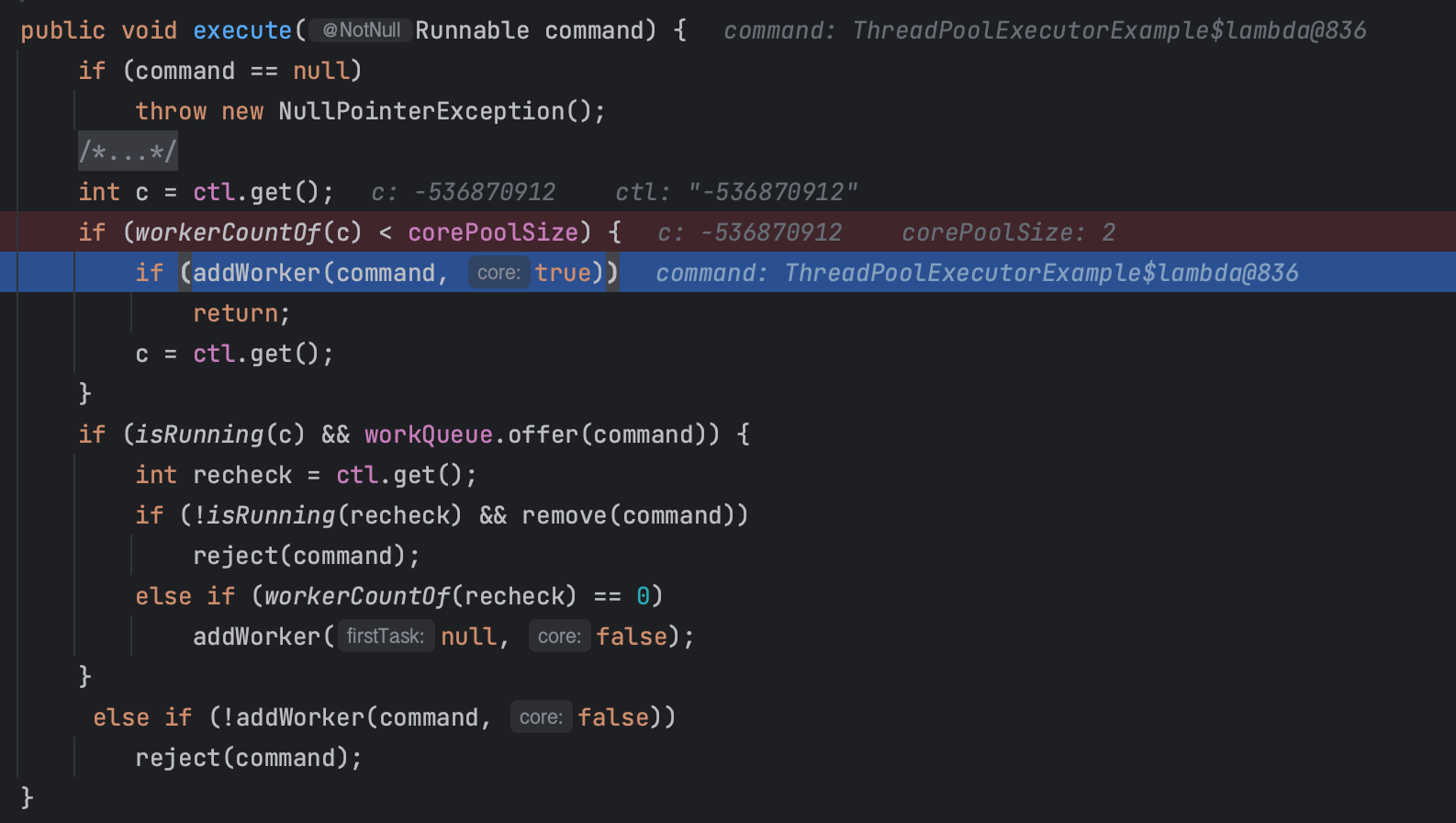
workerCountOf()메소드는 비트 마스킹을 활용해서 c의 하위 비트와 함께 현재 실행 중인 스레드의 수를 나타내는 비트 영역을 추출하기 위해 사용된다.
private static int workerCountOf(int c) {
return c & COUNT_MASK;
}
그 결과 현재 실행 중인 스레드 수가 corePoolSize보다 작은 경우, 그 다음 if문에 걸리면서 addWork()메소드에서 워커 스레드를 추가한다.
if (addWorker(command, true))
return;
이제 addWork()메소드의 내부 로직을 살펴보자.
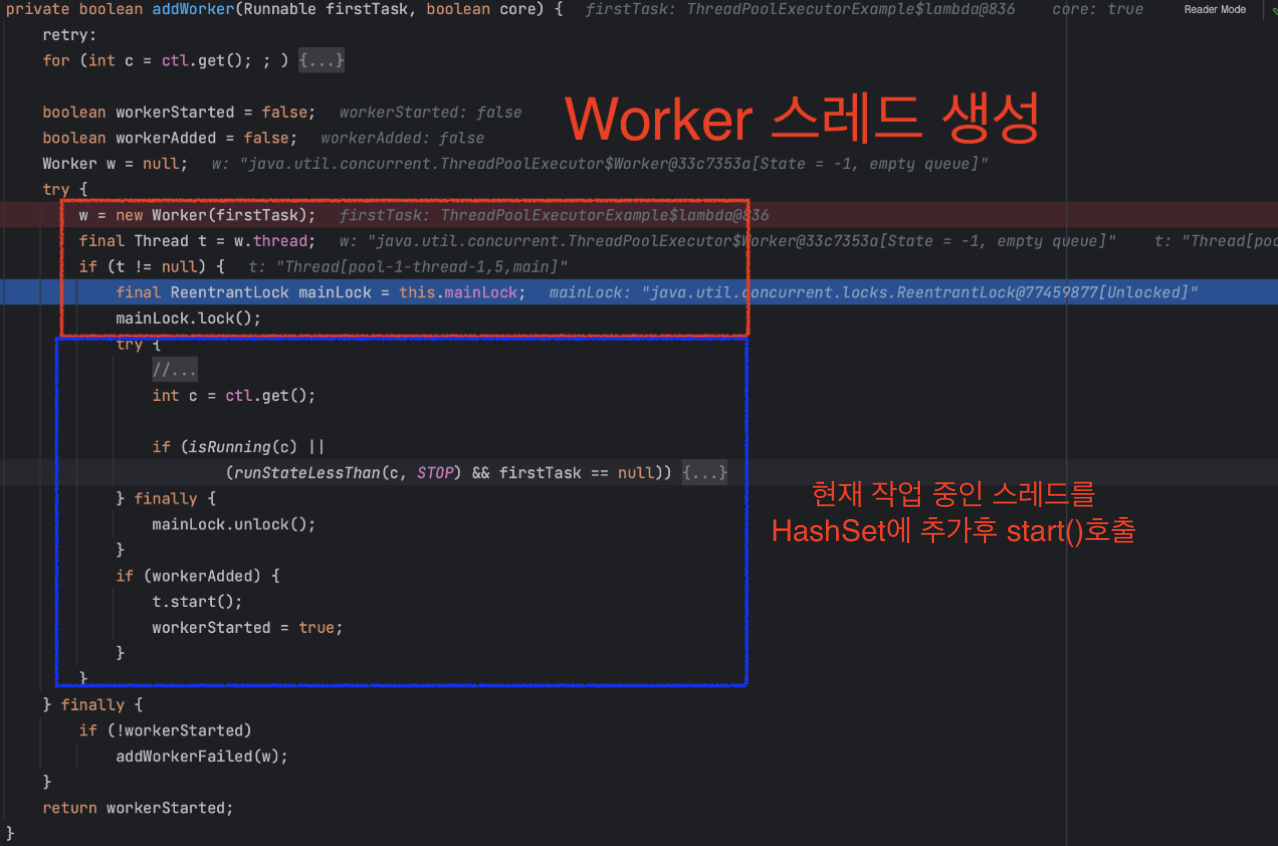
여기서 mainLock을 사용해서 임계 영역을 설정하는데, 스레드 풀의 상태를 변경하는 연산을 원자적으로 수행하기 위함이다.
스레드 풀에서는 여러 스레드가 동시에 스레드를 추가하거나 제거하려고 할 수 있기 때문에 ReentrantLock 을 사용해서 동시성 문제를 해결한다.
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();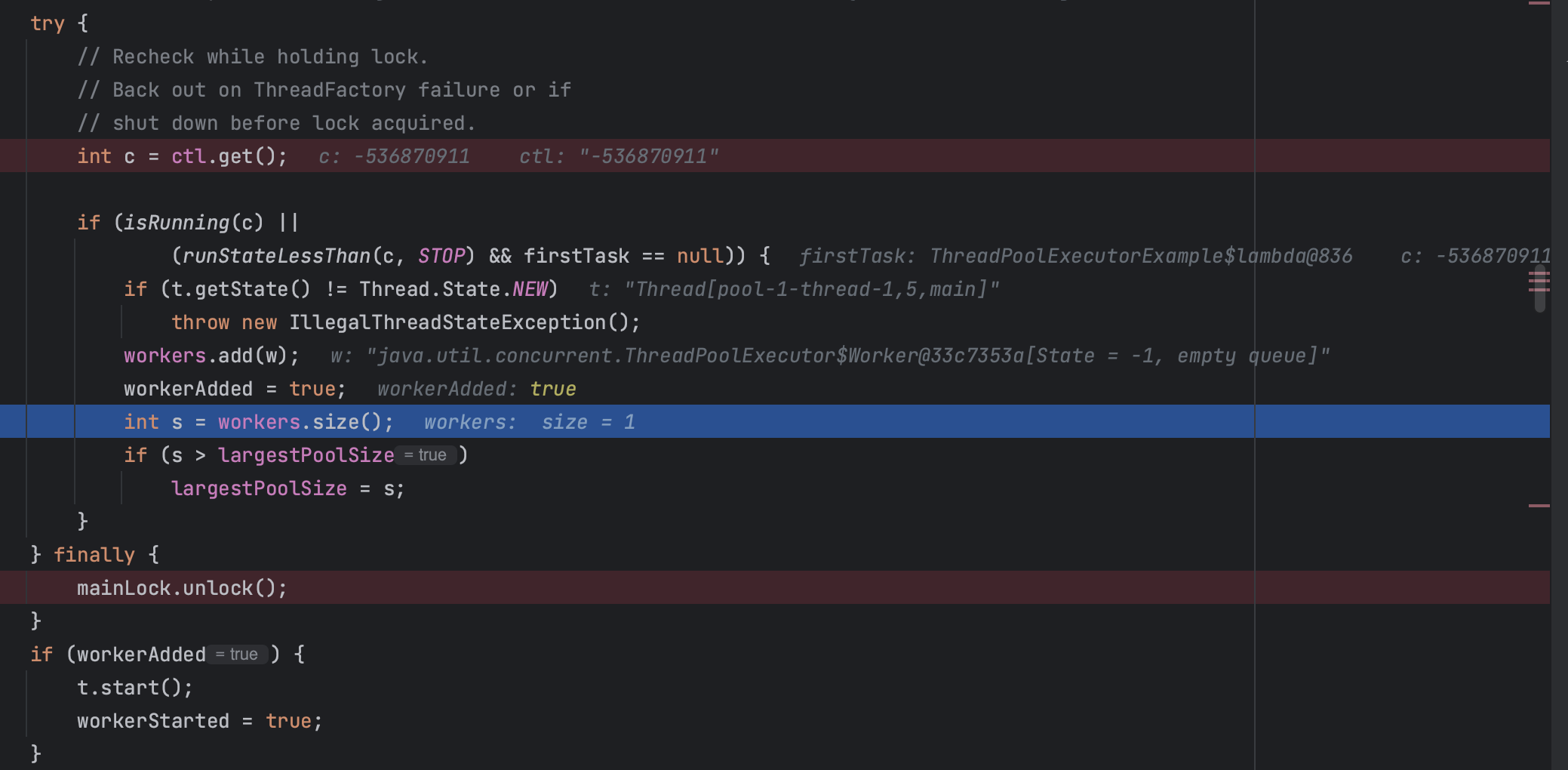

문서를 보면 스레드 풀에 있는 모든 워커 스레드를 포함하는 HashSet은 mainLock을 걸고 있을때만 접근이 가능하다고 되어있다.
아래 작업을 하는 이유는 스레드 풀에서 동시에 실행 중인 최대 워커 스레드 수를 추적하기 위함이다.
// 스레드 풀이 실행 중이거나, 스레드 풀이 종료 중이지 않고 첫 번째 작업이 null인 경우 스레드 추가
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
// Worker를 workers HashSet에 추가
workers.add(w);
workerAdded = true;
// workers HashSet의 크기 갱신
int s = workers.size();
if (s > largestPoolSize) // 현재까지의 최대 풀 크기
largestPoolSize = s;

워커 스레드 추적용 로직이 끝나면 mainLock을 해제하고, 해당 스레드의 start()메소드를 통해 스레드를 실행 시킨다.
그리고 다시 execute 메소드로 돌아와 return문으로 메소드를 종료한다.
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
이 작업은 ThreadPoolExecutor생성자에 넘겨주었던 Core Pool Size만큼 반복된다.
ThreadPoolExecutor executor = new ThreadPoolExecutor( // 디버깅하고자 했던 코드
2, // Core Pool Size
3, // Maximum Pool Size
0L, // Keep Alive Time
TimeUnit.MILLISECONDS, // Time Unit for Keep Alive
new LinkedBlockingQueue<>() // Work Queue
);
코어 스레드 수를 2개를 적어서 총 2번 반복되었는데, 코어 스레드 수 4개, 최대 스레드 수 5개로 테스트해봤더니 4번이 반복되었다.
execute메소드를 호출하면 초반에 스레드 풀에서 코어 스레드 수만큼 스레드를 생성하고 start()메소드를 호출한다.
이제 코어 스레드 수를 다 채웠으니 파란박스의 2번 내용을 살펴보자
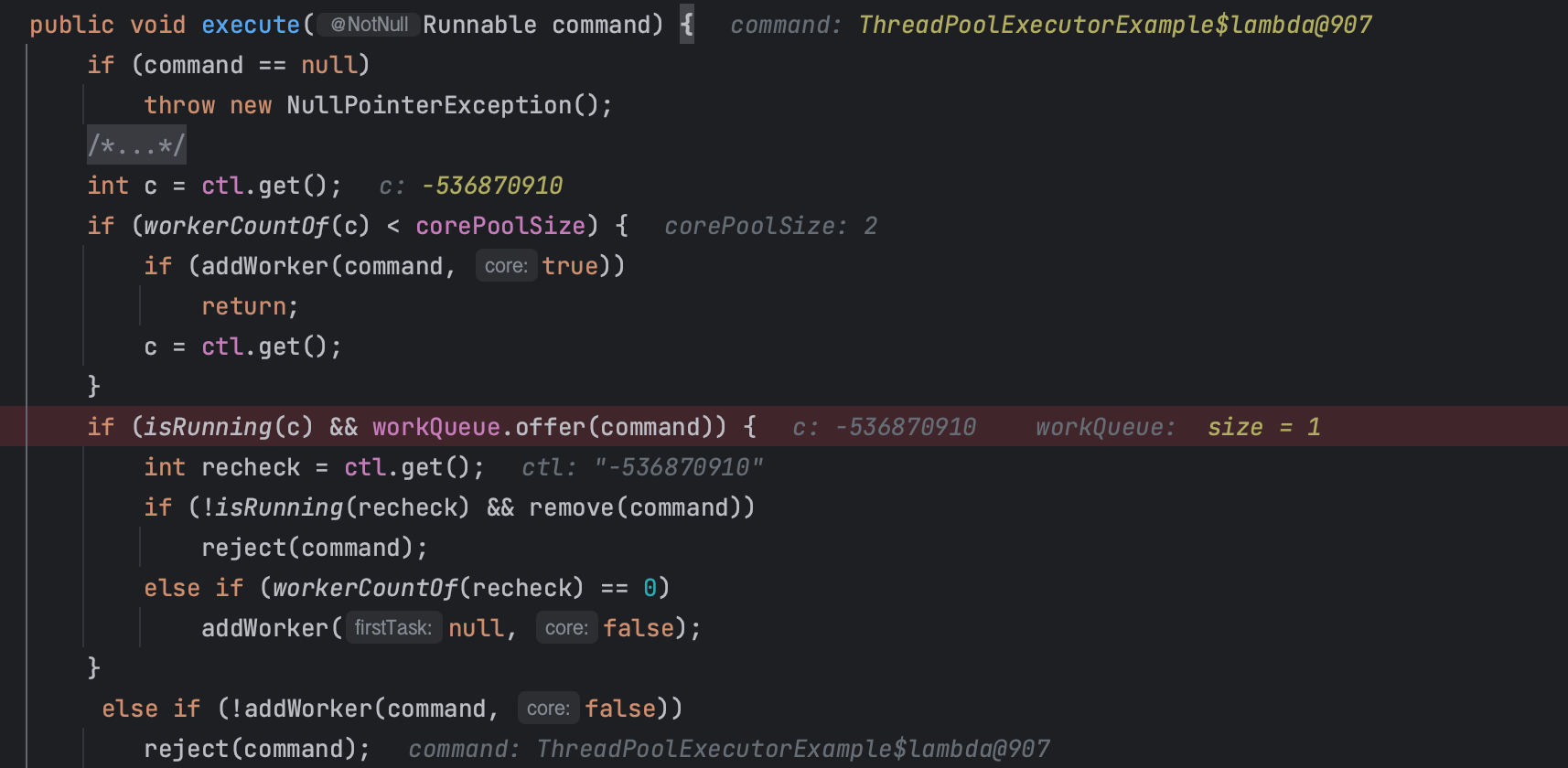
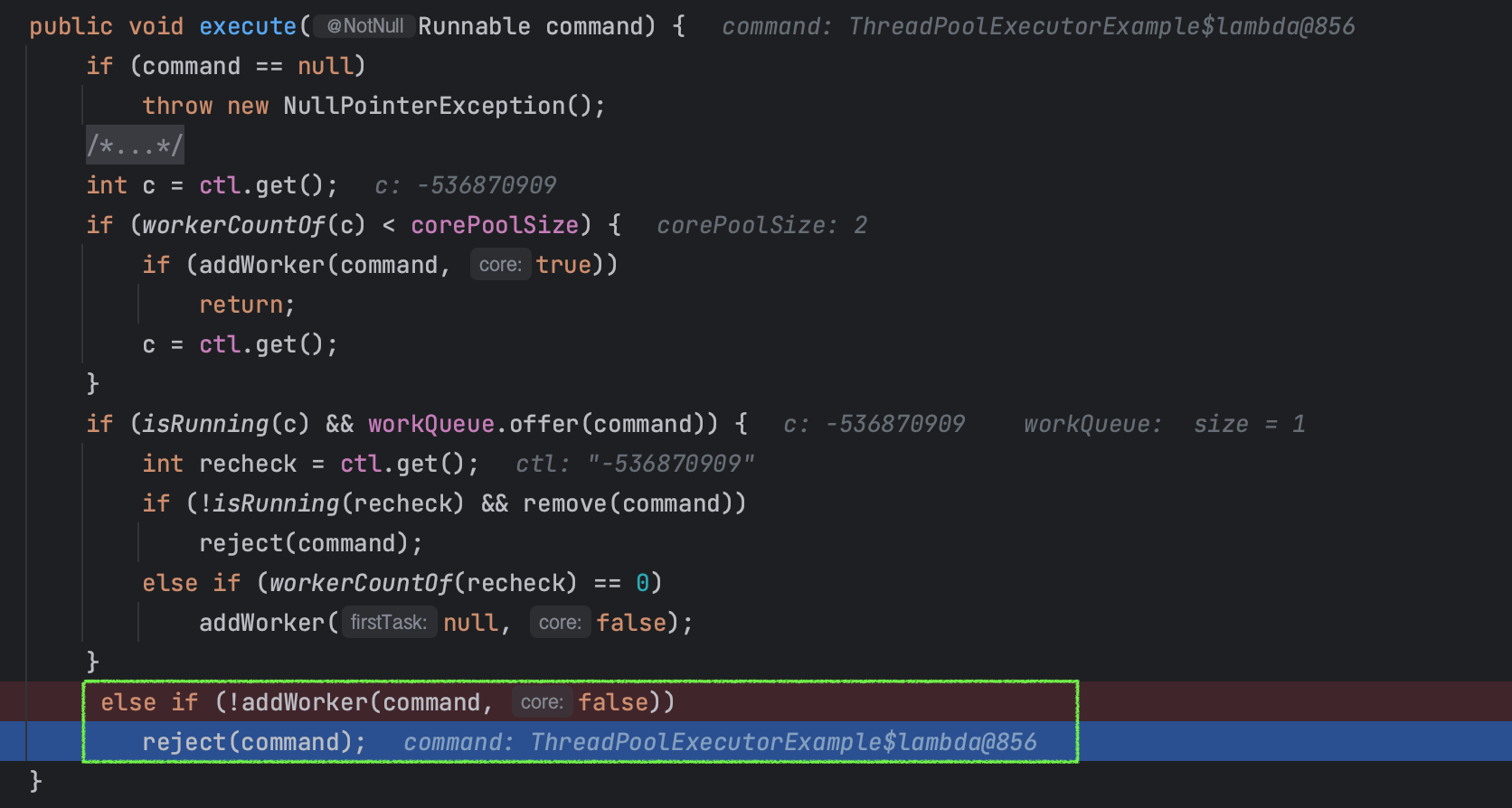
// 풀이 실행 중이고 작업을 작업 큐에 성공적으로 추가한 경우
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get(); // 다시 현재 컨트롤 상태를 가져옴
if (! isRunning(recheck) && remove(command)) // 실행 중이 아니고 command를 제거할 수 있는 경우
reject(command); // 작업을 거부
else if (workerCountOf(recheck) == 0) // 실행 중인 스레드가 없는 경우
addWorker(null, false); // 새 스레드 시작
}
workQueue는 작업(Runnable 객체)을 보유하고 워커 스레드에게 전달하는 데 사용되는 큐이다. offer 메소드는 작업을 큐에 추가하려고 시도하고, 만약 성공하면 true를 반환하며, 실패하면 false를 반환한다.
workQueue가 BlockingQueue의 구현체이기 때문에, 만약 큐가 가득 차 있어서 작업을 추가할 수 없다면 워커 스레드는 작업이 큐에 추가될 때까지 대기하게 된다.
여기서 ctl의 상태를 다시 한번 가져오는데, 큐에 작업을 추가한 후에 워커 스레드가 상태를 다시 한번 확인하기 위함이다.
이 시점에서 다른 스레드가 동시에 풀의 상태를 변경할 수 있으므로, ctl 변수를 읽어서 다시 최신의 상태를 확인하는 것이다.
int recheck = ctl.get();
recheck 변수를 통해 현재 스레드의 작업이 큐에 추가된 후에도 여전히 풀이 실행 중인지, 작업이 큐에서 제거되지 않았는지 확인한다.
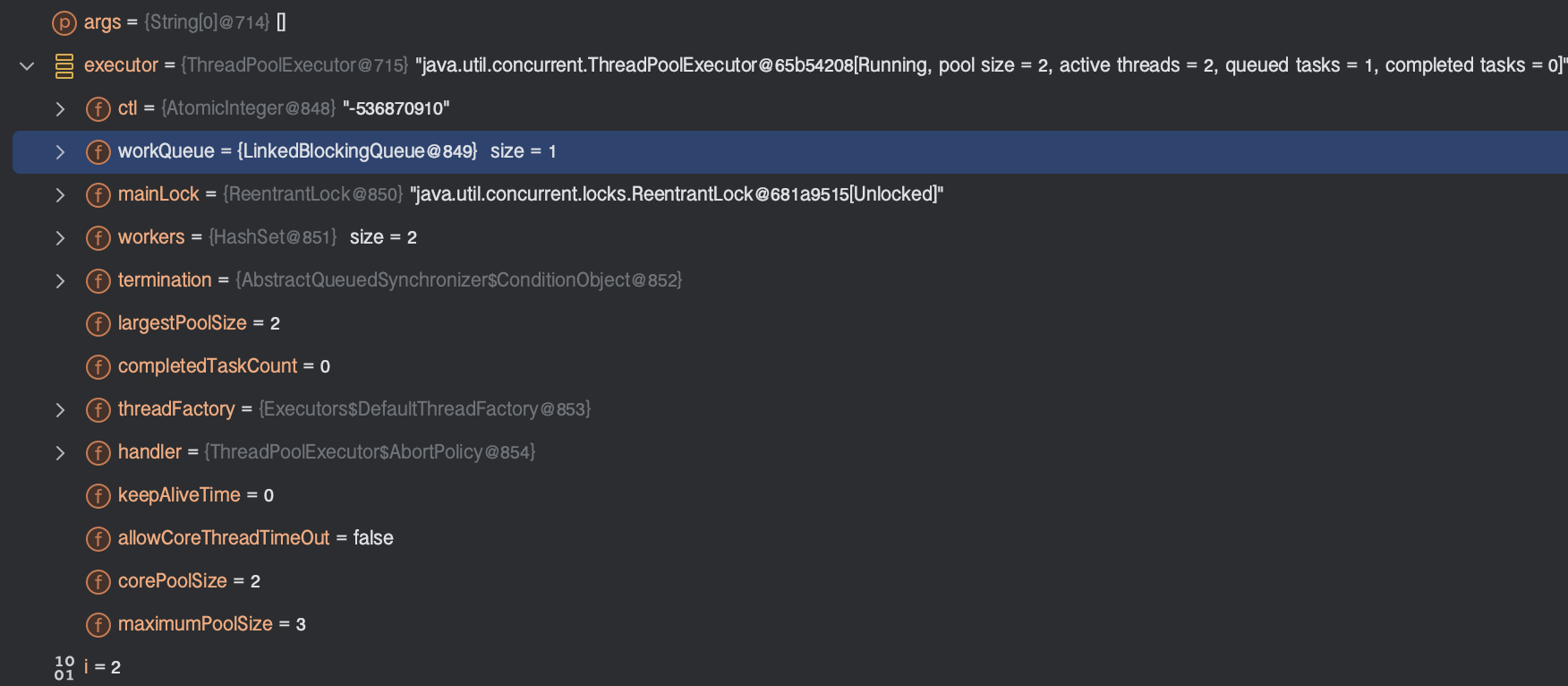
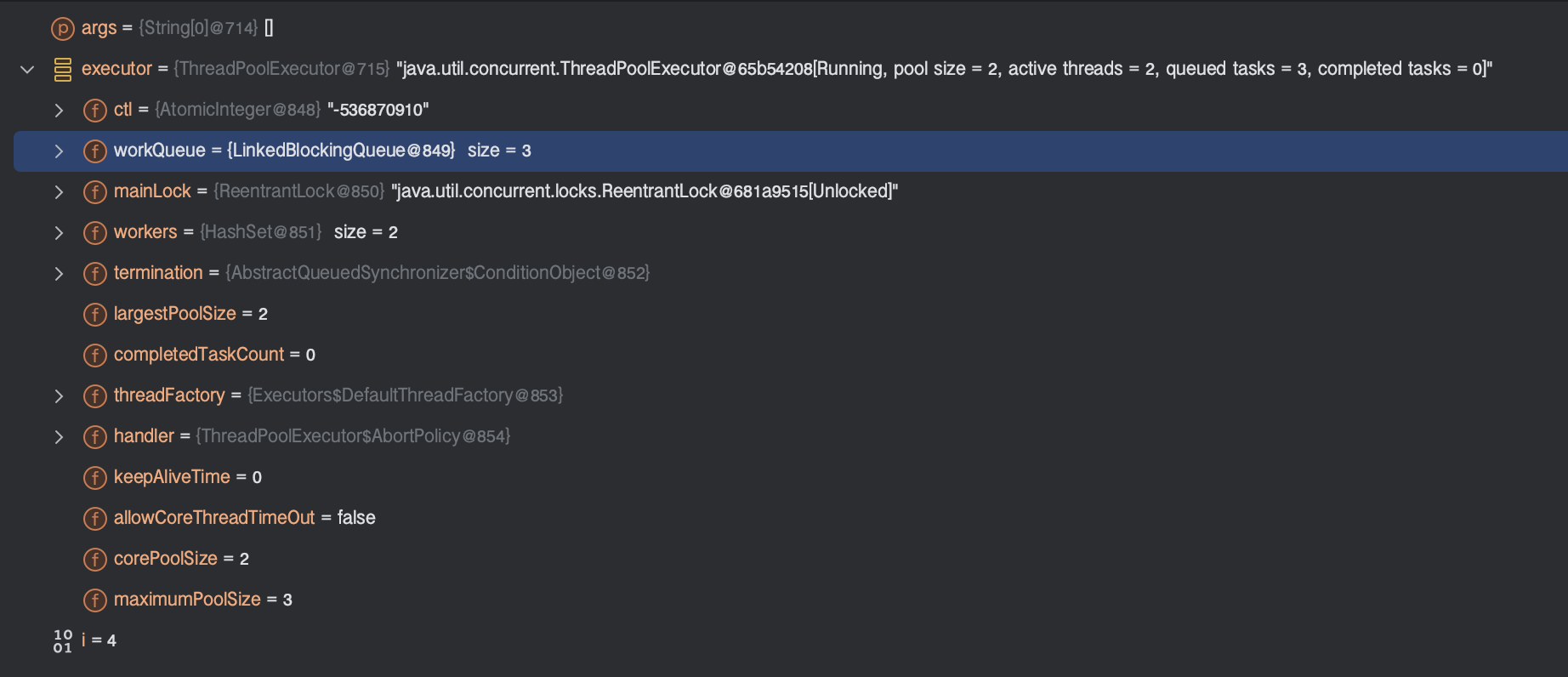
이 과정을 3번 반복한다.
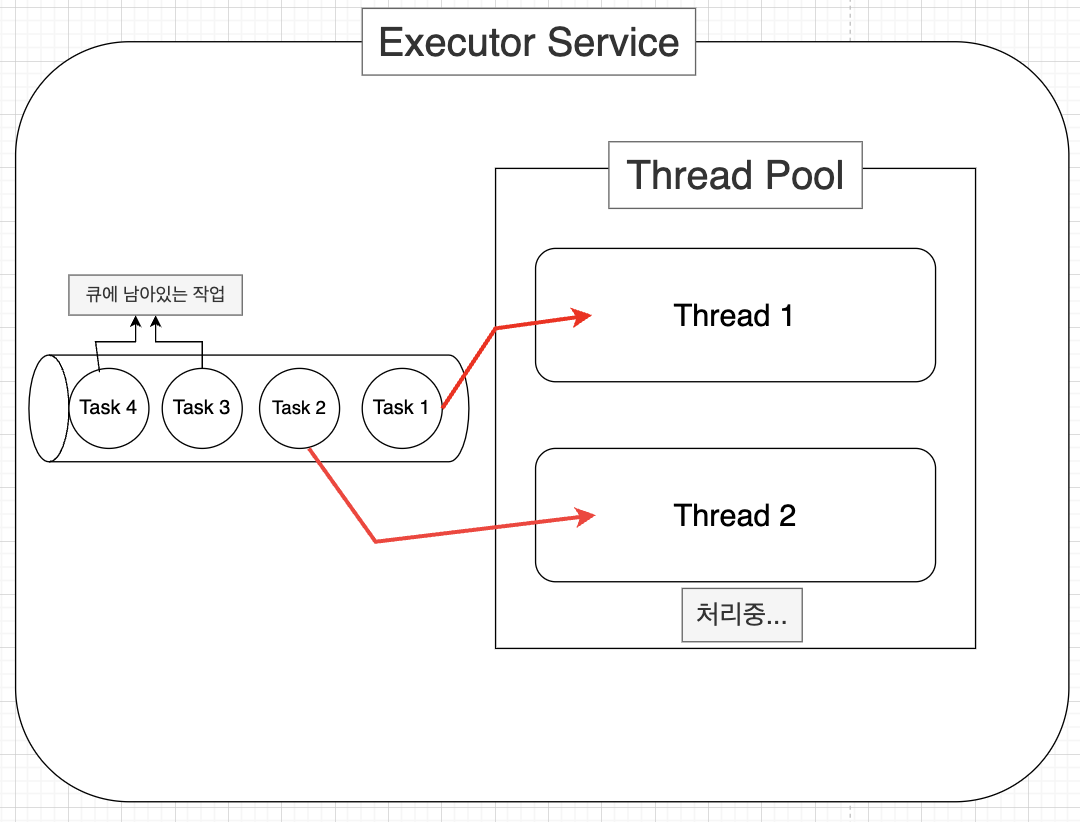
왜냐하면 작업의 생성을 5번 했고, 코어 스레드 수가 2개이자, 현재 워커 스레드가 2개인 상태이므로 나머지 3번은 작업 큐로 등록되어 대기한다. 이 대기 중인 작업들은 큐에서 꺼내와 스레드 풀의 워커 스레드에 의해 처리될때 까지 기다린다.
for (int i = 0; i < 5; i++) {
...
}

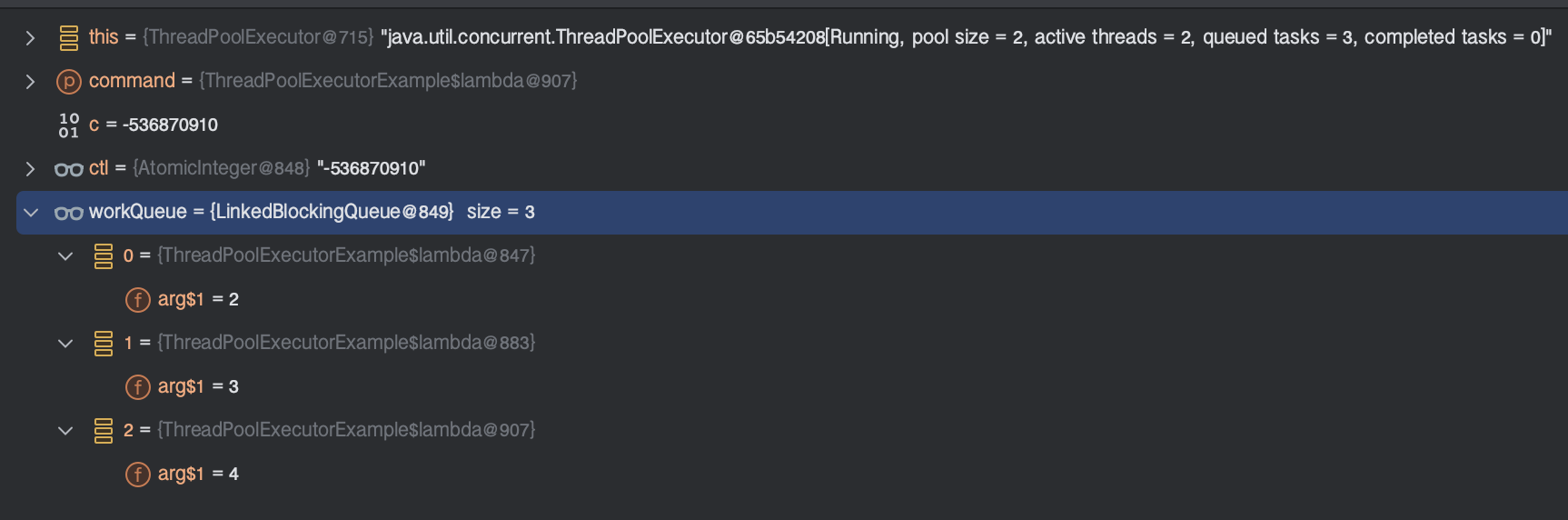
그리고 shoutdown을 하면 작업이 완료된 개수를 확인할 수 있다.
// 스레드 풀 종료
executor.shutdown();
// 스레드 풀이 종료될 때까지 대기
executor.awaitTermination(10, TimeUnit.SECONDS);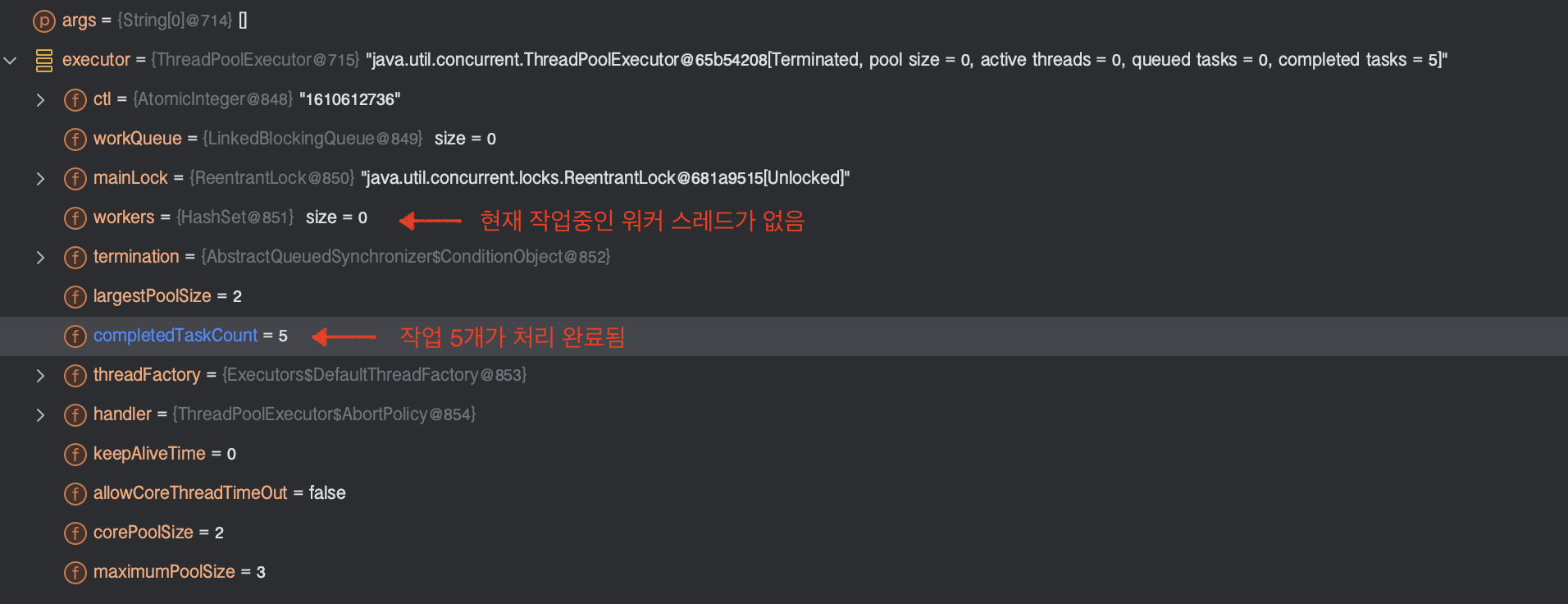
자 그러면 드디어 마지막 초록색 박스 3번째 로직은 언제 실행되는지 살펴보자.
else if (!addWorker(command, false))
reject(command);
이 경우는 큐가 가득 찼거나 스레드를 추가할 수 없는 경우를 의미한다.
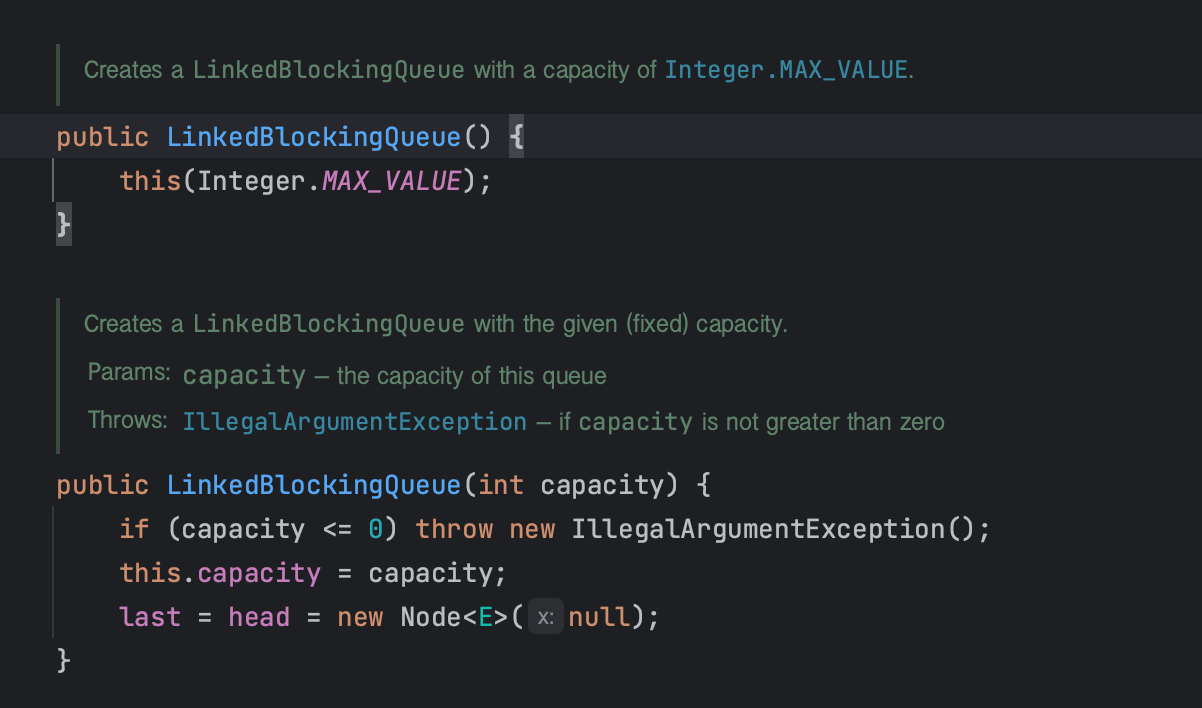
큐를 어떻게 가득차게 만들 수 있을까? LinkedBlockingQueue 생성자에 capacity를 정해주면 된다.
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2,
3,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1) // capacity 큐의 용량을 1로 설정
디버깅을 자세히 할 필요없이 바로 RejectedExecutionException 익셉션을 던져주는것을 볼 수 있다.
이건 스레드를 2개 생성하면서 작업 2개를 처리하고, 나머지들 중 1개가 작업 큐에 등록된 뒤 다음 작업부터 발생한다.
LinkedBlockingQueue로 작업 큐의 용량을 1로 해주었기 때문이다.
이렇게 execute메소드는 작업 처리 도중 예외가 발생하면 스레드가 종료되고, 해당 스레드는 스레드 풀에서 제거된다.
따라서 스레드 풀은 다른 작업 처리를 위해 새로운 스레드를 생성한다.
아래 걸과를 보면 이전 코드에서는 thread 2까지만 있었는데 thread3이 나온걸 보면 새로운 스레드가 추가되었다는 걸 알 수 있다.
[Running, pool size = 3, active threads = 3, queued tasks = 1, completed tasks = 0]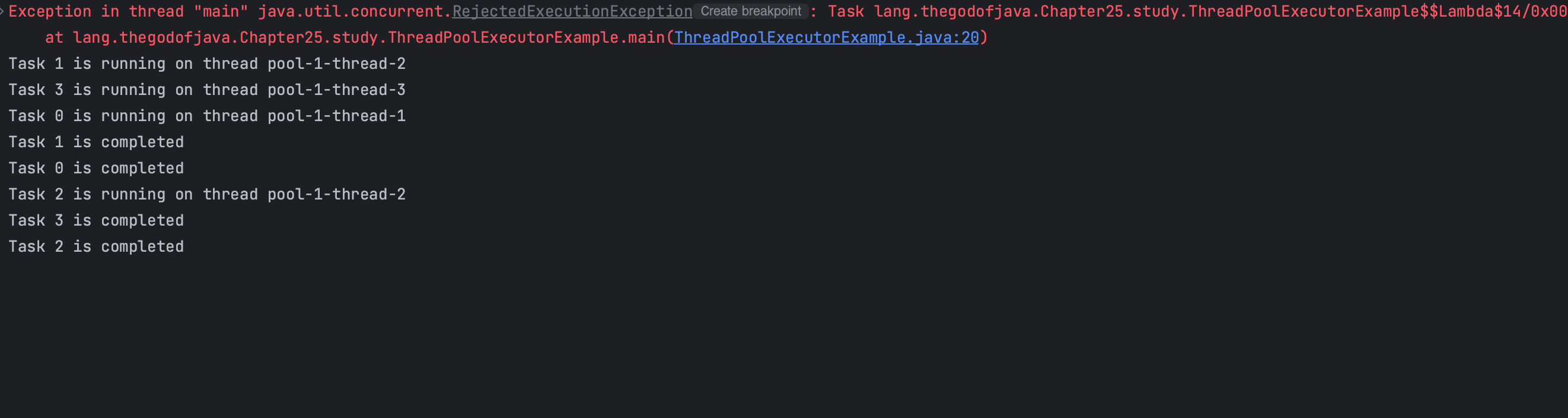
정리
- ExecutorService를 구현한 ThreadPoolExecutor 클래스로 스레드 풀을 생성하면 효율적이다.
- ThreadPoolExecutor 객체를 생성한다고 스레드가 바로 생성되는게 아니라, 스레드 풀이 생성되는 것이다.
- execute 메소드를 통해 스레드를 생성하고, 작업 큐에 작업을 등록할 수 있다.
- exectue메소드에서 먼저 코어 스레드 개수만큼 스레드를 생성한뒤 작업을 가져가서 처리하고, 스레드가 꽉 차있으면 작업 큐에 작업들을 등록한다.
- 큐가 꽉 차거나, 스레드를 더 이상 생성할 수 없을때 작업을 거부한다.
마무리
맨 처음에는 ThreadPoolExecutor만 디버깅해볼까 하다가, 전반적인 이해도를 높이기 위해서는 Executor, ExecutorService, Executors 모두 다 알아야 할 것 같아서 포스팅이 꽤나 길어졌다.
디버깅을 하는게 확실히 동작 원리를 이해하는데 많은 도움이 되긴 하는데, 시간이 엄청 오래 걸렸다.
사실 디버깅을 하는 것 자체는 그렇게 엄청 많이 오래 걸리진 않은 것 같은데, 여러 배경지식들 알고 접근하려다보니 하루를 다 썼다.
그래도 이제 멀티 스레딩에 대해 어느정도 원리를 파악한 것 같으니 너무 다행이다.
이제 java.util.concurrent패키지에 있는 모든 파일들도 다 한번씩 파헤쳐봐야 겠다.
참고 문서 및 블로그
https://yscho03.tistory.com/294
https://mangkyu.tistory.com/259
https://www.youtube.com/watch?v=Nb85yJ1fPXM&list=PLL8woMHwr36EDxjUoCzboZjedsnhLP1j4&index=13
https://leeyh0216.github.io/posts/truth_of_threadpoolexecutor/
https://blog.naver.com/bumsukoh/222175557879
https://jenkov.com/tutorials/java-util-concurrent/executorservice.html
'언어 > Java' 카테고리의 다른 글
| Exception Wrapping vs Rethrowing (0) | 2024.03.25 |
|---|---|
| 왜 자바 직렬화는 Serializable 인터페이스가 있어야할까? (0) | 2024.01.30 |
| HashMap이 동작하는 원리를 파헤쳐보자 + putVal메소드 디버깅 (0) | 2024.01.21 |
| [Java] String 덧셈 연산의 컴파일 최적화에 대해 알아보자 (0) | 2024.01.12 |
| Comparator로 보는 인터페이스와 정적 메서드 (1) | 2023.12.27 |


