
개발자는 기록이 답이다
혼공 컴퓨터구조 + 운영체제 3. 소스코드와 명령어 본문
프로그래밍 언어로 작성한 소스 코드가 컴퓨터 내부에서 명령어가 되고 실행되는 과정을 학습한다.
명령어의 구조와 주소 지정 방식을 학습하며 명령어의 생김새와 작동 원리를 이해한다.

1. 소스코드와 명령어
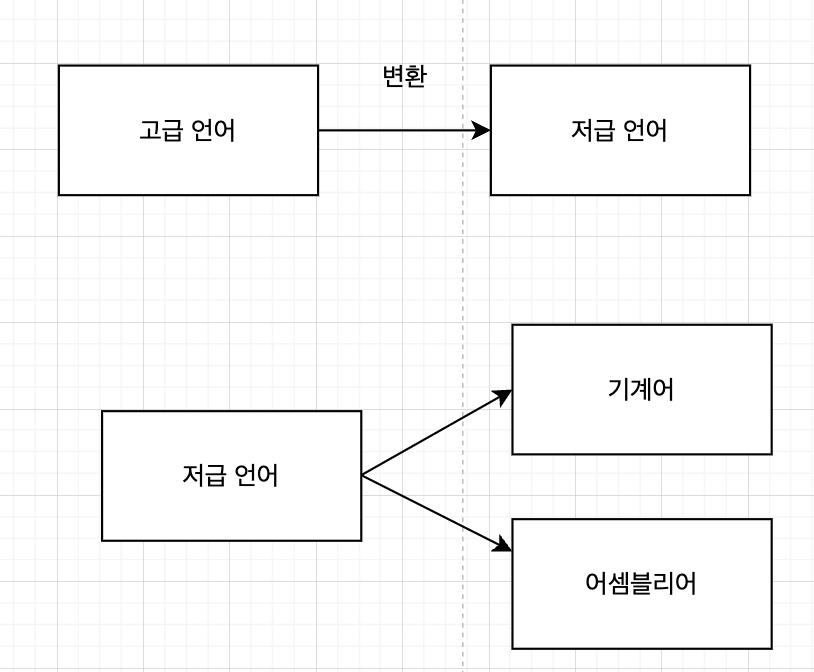
고급언어와 저급언어
- 고급 언어 : 사람이 이해하고 작성하기 쉽게 만들어진 언어
- 저급 언어 : 컴퓨터가 이해하고 실행할 수 있는언어
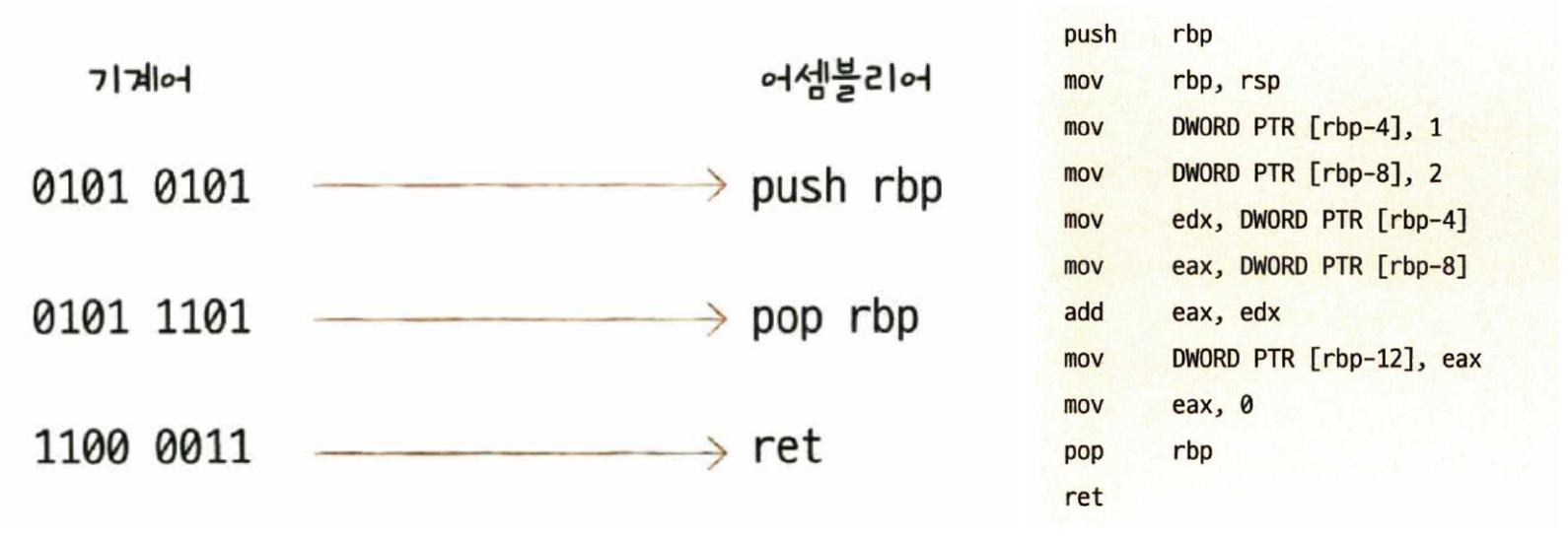
- 기계어 : 0과 1의 명령어 비트로 이루어진 언어, 너무 길어지기 때문에 십육진수로 표현하기도 한다.
- 어셈블리어 : 기계어를 읽기 편한 형태로 번역한 언어

개발자들이 고급언어로 소스 코드를 작성하면 알아서 저급언어로 변환되어 잘 실행되는데. 저급 언어를 알아야 할까?
하드웨어와 밀접하게 맞닿아 있는 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보 보안 분야 등의 개발자는 어셈블리어를 많이 사용한다. 이런 분야 개발자들에게는 어셈블리어를 읽으면 컴퓨터가 프로그램을 어떤 과정으로 실행하는지, 즉 프로그램이 어떤 절차로 작동하는지를 가장 근본적인 단계에서부터 하나하나 추적하고 관찰할 수 있다.
컴파일 언어와 인터프리터 언어
고급 언어에서 저급언어로 어떻게 변환될까?
- 컴파일 : 컴파일 방식으로 작동하는 프로그래밍 언어
- 인터프리터 : 인터프리트 방식으로 작동하는 프로그래밍 언어

컴파일 언어

- 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는고급 언어이다.
- 컴파일 : 컴파일 언어로 작성된 소스 코드는 코드 전체가 저급 언어로 변환되는 과정
- 대표적인 컴파일 언어 : C
- 컴파일러를 통해 저급 언어로 변환된 코드를 목적 코드라고 한다.
인터프리터 언어
- 인터프리터 언어 : 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어
- 인터프리터 : 소스 코드를 한 줄 식 저급 언어로 변환하여 실행
- 대표적인 인터프리터 언어 : Python
- 소스코드 전체가 저급 언어로 변환되는 컴파일 언어와 달리, 인터프리터 언어는 소스코드를 한줄 씩 한 줄씩 차례대로 실행한다,
- 소스 코드 내에 오류가 하나라도 있으면 컴파일이 불가능한 컴파일 언어
- 소스 코드를 한 줄씩 실행하기 때문에 소스코드 N번째 줄에 문법 오류가 있더라도 N-1째 줄까지 올바르게 수행하는 인터프리터 언어
- 인터프리터 언어가 컴파일 보다 느리다
- 컴파일 언어는 컴파일을 통해 나온 결과물, 즉 목적 코드는 컴퓨터가 이해하고 실행할 수 있는 저급 언어인 반면,
- 인터프리터 언어는 소스 코드 마지막에 이를 때 까지 한줄 한줄 저급 언어로 해석하면서 실행해야 하기 때문이다.
컴파일 언어와 인터프리터 언어, 칼로 자르듯이 구분 안된다.
- C, C++과 같이 명확하게 구분할 수 있는 언어도 있으나,
- 현재 많은 프로그래밍 언어는 경계가 모호하다.
- 인터프리터 언어로 알려진 Pyhon도 컴파일을 하지 않는 것은 아니며,
- Java의 경우 저급 언어가 되는 과정에서 컴파일과 인터프리터를 동시에 수행한다.
- 단지, 고급 언어가 저급 언어로 변환되는 대표적인 방법에 컴파일방식, 인터프리터방식이 있다고 생각하면 된다.
목적 파일 vs 실행 파일
- 이미지 파일 : 이미지로 이루어진 파일
- 텍스트 파일 : 텍스트로 이루어진 파일
- 목적 파일 : 목적 코드로 이루어진 파일
- 컴퓨터가 이해하는 저급 언어인 목적 코드
- 목적 코드가 실행 파일이 되기 위해서는 링킹작업을 거쳐야 한다.
- 실행 파일 : 실행 코드로 이루어진 파일
2. 명령어의 구조
저급 언어는 명령어들로 이루어져 있다는데, 그럼 명령어 하나하나는 어떻게 생겼을까?
연산 코드와 오퍼랜드
- 명령어 : 연산 코드 + 오퍼랜드
- 연산 코드 : 명령어가 수행할 연산(연산자)
- 오프랜드 : 연산에 사용할 데이터, 연산에 사용할 데이터가 저장된 위치(피연산자)

아래 그림에서 주황배경이 있는 곳이 연산 코드 필드, 하얀 배경이 오퍼랜드 필드이다.

기계어와 어셈블리어도 명령어이기 때문에 연산코드와 오퍼랜드로 구성되어있다.
붉은 글씨가 연산 코드, 검은 글씨가 오퍼랜드이다.
오퍼랜드(=주소 필드)
- 오퍼랜드 필드에는 연산에 사용할 데이터가 저장된 위치, 메모리나 레지스터 주소가 있다.
- 오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 한개 만 있을 수도, 2~3개 있을 수도 있다.
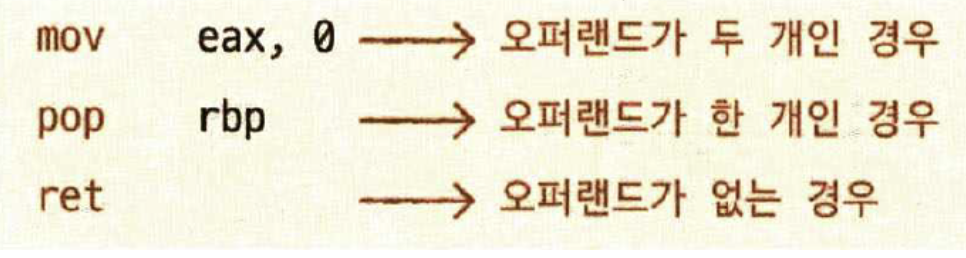
오퍼랜드가 0개 : 0-주소 명령어
오퍼랜드가 1개 : 1-주소 명령어

연산 코드
명령어의 종류와 생김새는 CPU마다 다르기 때문에 연산 코드의 종류와 생김새도 다 다르다.
대부분의 CPU가 이해하는 대표적인 연산 코드 종류로만 이해해보자.
- 데이터 전송
- MOVE : 데이터를 옮겨라
- STORE : 메모리에 저장해라
- LOAD (FETCH) : 메모리에서 CPU로 데이터를 가져와라
- PUSH : 스택에 데이터를 저장해라
- POP : 최상단 데이터를 가져와라
- 산술 논리 연산
- ADD, SUBTRACT, MULTIPLY, DIVIDE - 산술연산을 수행하라
- INCREMENT, DECREMENT - 오퍼랜드에 1을 더하라/빼라
- AND, OR, NOT - 해당 연산을 수행하라
- COMPARE - 두 숫자 / TRUE, FALSE 값을 비교하라
- 제어 흐름 변경
- JUMP : 특정 주소로 이동해 실행 순서 변경
- CONTITIONAL JUMP : 특정 조건에 부합시 주소 이동해 실행 순서 변경
- HALT : 프로그램 실행 멈춰라
- CALL : 되돌아올 주소 저장한 채 특정 주소로 실행순서를 옮겨라
- RETURN : CALL 에서 저장한 주소로 돌아가라
- 입출력 제어
- READ (INPUT) : 특정 입출력 장치로부터 데이터 읽어라
- WRITE (OUTPUT) : 특정 입출력 장치로 데이터를 써라
- START IO : 입출력 장치를 시작하라
- TEST IO : 입출력 장치 상태를 확인하라
주소 지정 방식
왜 오퍼랜드 필드에 메모리나 레지스터의 주소를 담는걸까?
그냥 연산 코드, 연산 코드에 사용될 데이터 형식으로 명령어를 구성하면 되지 않나?
명령어 길이가 정해져있기 때문에 안된다.
하나의 명렁어가 n비트로 구성되어 있고, 그중 연산 코드 필드가 m비트라고 가정할 경우,
오퍼래드 필드에 가장 많은 공간을 할당할 수 있는 1-주소 명령어라 할지라도 오퍼랜드 필드의 길이는 연산 코드만큼의 길이를 뺀 n-m비트가 된다. 오퍼랜드 개수가 많아질 수록 오퍼랜드 필드의 크기는 더욱 작아진다.
만약 오퍼랜드 필드에 메모리 주소가 담긴다면 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다.
레지스터의 이름을 명시할 때에도 마찬가지이다. 표현할 수 있는 정보의 가짓수는 레지스터가 저장할 수 있는 공간만큼 커진다.


유효 주소 : 연산 코드에 사용될 데이터가 저장된 위치
- 첫번째 그림의 유효주소는 10번지
- 두번째 그림의 유효주소는 R1
주소 지정 방식 : 오퍼랜드 필드에 데이터가 저장된 위치를 명시할때 연산에 사용할 데아터 위치를 찾는 방법
- 즉지 주소 지정 방식 : 연산에 사용할 데이터
- 직접 주소 지정 방식 : 유효 주소(메모리 주소)
- 간접 주소 지정 방식 : 유효주소의 주소
- 레지스터 주소 지정 방식 : 유효 주소(레지스터 이름)
- 레지스터 간접 주소 지정 방식 : 유효 주소를 저장한 레지스터
즉시 주소 지정 방식
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 데이터의 크기가 작아지는 단점이 있지만, 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는과정이 없어서 빠르다.

직접 주소 지정 방식
- 오퍼랜드 필드에 유효 주소를 직접 명시
- 오퍼랜드 필드에서 표현할 수 있는 데이터의 크기는 즉시 주소 지정방식보다 커짐
- 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 표현할 수 있는 유효 주소에 제한이 생긴다.

간접 주소 지정 방식
- 유효 주소의 주소를 오퍼랜드 필드에 명시
- 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 넓어짐
- 두 번의 메모리 접근이 필요하기 때문에 앞서 말한 주소 지정 방식보다 느림

레지스터 주소 지정 방식
- 직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시
- CPU 외부에 있는 메모리에 접근하는 것보다 CPU 내부에 있는 레지스터에 접근하는게 더 빠르다.
- 직접 주소 지정방식보다 빠르다.
- 직접 주소 지정 방식처럼 표현할 수 있느 ㄴ레지스터 크기에 제한이 생긴다는 단점이 있다.

레지스터 간전 주소 지정 방식
- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시한다.
- 간전 주소 지정방식과 비슷하지만, 메모리에 접근하는 횟수가 한 번으로 줄어들어서 더 빠르다.

🤔느낀점
이번 3장을 통해서, 개발자는 본인이 사용하는 프로그래밍 언어가 어떻게 컴파일과 인터프리트가 되는지 알 수 있는 기회였다.
자바 같은 경우도 JVM을 통해 어떻게 컴파일 되는지 다시 한번 생각해봤다.
Java 소스코드는 자바 컴파일러(Javac)에 의해 바이트 코드로 변환이 되고,
이러한 바이트 코드를 JVM에 의해 인터프리트 되거나, JIT컴파일러에 의해 OS별로 기계어로 번역된다.
그러면 javac에 의해 변환된 바이트 코드가 목적코드라고 할 수 있을까?
목적코드는 컴파일러에 의해 고급 언어로 부터 생성된 저급 언어로 변환된 코드를 나타낸다.
또한, 목적 코드는 링킹 작업을 통해 실행코드로 변환된뒤에 실행된다는 것을 떠올리자.
Java에서 javac컴파일러가 Java소스 코드를 컴파일하여 생성한 바이트코드는 JVM에서 실행 되기 전에 목적 코드로 볼 수 있다.
JVM내부에서 인터프리터 또는 JIT(Just-In-Time) 컴파일러에 의해 실행 코드로 변환되기 때문에 목적 코드라고 불릴 수 있을 것 같다.
그렇다면 Java에서는 링킹 작업은 언제하는 걸까?
C나 C++와 같은 컴파일 언어와 다르게 런타임에 이루어지며, 명시적인 링킹 작업을 하지 않는다.
컴파일과 인터프리트 과정 중 클래스 로딩과 동시에 자동으로 이뤄지며 명시적인 링커 단계가 필요하지 않는다.
- 클래스 로딩 (Class Loading):
Java 프로그램이 실행될 때, 클래스 로더가 필요한 클래스 파일을 찾아서 메모리에 로드합니다. 이 과정에서는 클래스 파일이 유효한지 확인하고, 필요한 다른 클래스들도 로드합니다. - 링킹 (Linking):
Verification (검증): 클래스 파일의 유효성을 검사하여 올바른 형식인지 확인합니다.
Preparation (준비): 클래스의 정적 변수들을 초기화하고 기본값으로 채웁니다.
Resolution (해결): 클래스나 인터페이스의 심볼릭 레퍼런스를 실제 메모리 주소로 연결합니다. - 초기화 (Initialization):
클래스의 정적 변수들을 초기화하는 단계입니다. 이때 클래스의 static 블록이 실행되어 초기화 작업이 수행됩니다.
소스코드를 컴파일하면 명령어가 되고, 명령어는 연산코드랑 오퍼랜드로 구성되어있고,
오퍼랜드의 주소 지정 방식이 5개정도되는걸 떠올려보자.
주소 지정 방식을 명시적으로 개발자가 지정해 줄 수 있을 것 일까?
프로그래밍 언어 자체보다는 컴퓨터 아키텍처, 운영체제 쪽에 더 연관되어 있는 개념이라 상관이 없는 것일까?
GPT선생님께서 얘기하시길 Java는 일반적으로 메모리 주소를 직접 다루지 않지만, 몇 가지 예시를 통해 주소 지정 방식이 어떻게 활용하는지 예시가 있다고 한다.
1. 배열의 주소 지정 방식
Java에서 배열을 다룰 때는 인덱스를 사용한 간접 주소 지정 방식
public class ArrayExample {
public static void main(String[] args) {
int[] numbers = {1, 2, 3, 4, 5};
// 간접 주소 지정 방식
int valueAtIndex2 = numbers[2];
System.out.println("Value at index 2: " + valueAtIndex2);
}
}
2. 직접 주소 지정 방식
Java에서는 직접적인 메모리 주소에 대한 접근이 허용되지 않는다.
하지만, JNI를 사용하여 네이티브 언어와 상호 작용할 때 주소 지정 방식을 활용할 수 있다.
public class NativeMethodExample {
// JNI를 통해 호출될 네이티브 메서드
private native void nativeMethod(int[] array);
public static void main(String[] args) {
NativeMethodExample example = new NativeMethodExample();
int[] numbers = {1, 2, 3, 4, 5};
// JNI를 통해 주소 지정 방식 활용
example.nativeMethod(numbers);
}
// 네이티브 메서드의 구현은 C 또는 C++ 등의 네이티브 언어에서 이루어짐
static {
System.loadLibrary("NativeLibrary");
}
}위의 코드에서 nativeMethod는 Java에서 호출되지만, 해당 메서드의 구현은 네이티브 언어에서 이루어지므로 네이티브 메서드에서 직접적으로 메모리 주소에 접근할 수 있습니다.
이러한 예시에서 보듯이, Java에서는 주소 지정 방식을 직접 다루는 것이 아니라 간접적으로 다루는 경우가 더 많습니다. 또한, 이러한 기능을 활용할 때에는 주의가 필요하며, 주소 지정 방식을 사용하는 일반적인 Java 코드는 드물기 때문에 실무에서는 특정 상황에서 JNI 등을 사용하여 네이티브 코드와의 상호 작용에 활용됩니다.
'CS > 운영체제' 카테고리의 다른 글
| 혼공 컴퓨터구조 + 운영체제 5. CPU 성능 향상 기법 (Mac M2 코어 개수 확인 방법) (0) | 2024.01.06 |
|---|---|
| 혼공 컴퓨터구조 + 운영체제 4. CPU 작동원리 (1) | 2023.12.23 |
| 혼공 컴퓨터구조 + 운영체제 2. 데이터 (0) | 2023.12.20 |
| 혼공 컴퓨터구조 + 운영체제 1. 컴퓨터 구조 시작하기 (1) | 2023.12.20 |
| 운영체제 Ch.7 - 프로세스(process)와 스레드(thread)의 차이 (0) | 2023.10.17 |



