
개발자는 기록이 답이다
혼공 컴퓨터구조 + 운영체제 4. CPU 작동원리 본문
ALU와 제어장치가 어떤 정보를 내보내고 받아들이는지를 중심으로 두 장치의 역할을 학습하자.
또한, 레지스터를 통해 명령어가 처리되는 과정과
CPU가 하나의 명령어를 처리하는 사이클과 그 흐름을 방해하는 인터럽트에 대해 알아보자.

ALU(계산하는 부품)
1+2를 계산할 때 1과 2라는 피연산자와 더하기라는 수행할 연산이 필요하듯, ALU가 계산을 하기 위해 피연산자와 수행할 연산이 필요하다.

ALU가 받아들이는 정보
- 피연산자
- 제어신호
레지스터를 통해 피연산자를 받아들이고, 제어장치로부터 수행할 연산을 알려주는 제어 신호를 받아들인다.
ALU는 레지스터와 제어장치로부터 받아들인 피연산자와 제어 신호를 산술 연산, 논리 연산 등 다양한 연산을 수행한다.
ALU가 내보내는 정보
- 결과값
- 플래그
연산을 수행한 결과는 특정 숫자,문자,메모리 주소가 될 수 있고, 이 결과값은 바로 메모리에 저장되는게 아니라 일시적으로 레지스터에 저장된다. CPU가 메모리에 접근하는 속도는 레지스터에 접근하는 속도보다 훨씬 느리다.
ALU가 연산할 때 마다 결과를 메모리에 저장한다면 당연하게도 CPU는 메모리에 자주 접근하게 되고, CPU가 프로그램 실행 속도를 늦추게된다. 또한, 연산 결과에 대한 추가적인 정보를 내보내야 할때 플래그를 내보낸다.
※ 연산 결과가 연산 결과를 담을 레지스터보다 큰 상황을 오버플로우라고 한다.

플래그는 플래그 레지스터에 저장된다.
ALU가 연산을 수행한 직후 부호 플래그가 1이 되었다면 연산 결과는 음수 인것을 알 수 있다.

※ 깜짝 문제
CPU의 ALU가 연산한 결과로 레지스터에 101₍₂₎, 플래그 레지스터의 부호 플래그가 1일 경우, 해당 계산 결과의 십진수는?
- 정답 : -3
- 해설 : 101₍₂₎는 011₍₂₎에 2의 보수를 취해 음수로 표현한 값이며, 011₍₂₎을 십진수로 할 경우 3이다.
만약 제로 플래그가 1이 되었으면 연산 결과는 0임을 알 수 있다.

제어장치(제어 신호를 내보내고, 명령어를 해석하는 부품)
제어 신호 : 컴퓨터 부품을 관리하고 작동시키기 위한 전기 신호

제어장치가 받아들이는 정보
- 클럭 신호
- 클럭? 컴퓨터의 모든 부품을 움직이게 하는 시간 단위
- 클럭 주기에 맞춰 한 레지스터에서 다른 레지스터로 데이터가 이동되거나, ALU에서 연산이 수행되거나, CPU가 메모리에 젖아된 명령어를 읽거나
- 클럭 주기에 맞출 뿐, 한 클럭 마다 작동하는게 아님
- 명령어: 명령어 레지스터로부터 받아들인 명령어
- 플래그: 플래그 레지스터로부터 받아들인 플래그 값
- 제어 신호: 시스템 버스의 제어 버스로부터 받아들인 제어 신호
제어장치가 "제어 신호"를 내보내는 목적지
- CPU 내부의 레지스터 (레지스터간 데이터 이동 및 레지스터에 저장된 명령어 해석)
- CPU 내부의 ALU (수행할 연산 지시)
- CPU 외부의 제어버스 → 메모리 또는 입출력 장치(보조기억장치)
레지스터
레지스터는 CPU 내부의 작은 임시저장장치로, 프로그램 속 명령어와 데이터는 실행 전후에 반드시 레지스터에 저장된다.
반드시 알아야 할 레지스터
CPU 마다 레지스터의 종류가 다르지만, 공통적인 레지스터는 8개이다.
- 프로그램 카운터(PC, Program Counter): 메모리에서 가져올 다음에 실행할 명령어의 주소를 저장한다.(명령어 포인터라고도 불림)
- 명령어 레지스터(IR, Instruction Register): 현재 실행 중인 명령어를 저장한다.
- 메모리 주소 레지스터(MAR, Memory Address Register): 메모리에 접근할 때 사용하는 메모리의 주소를 저장한다.
- 메모리 버퍼 레지스터(MBR, Memory Buffer Register): 메모리에 접근할 때 사용하는 데이터를 저장한다.
- 범용 레지스터(AX, BX, CX, DX): 연산에 사용되는 주소, 데이터 모두를 저장한다.
- 플래그 레지스터(FR, Flag Register): 연산 결과에 대한 부가적인 상태 정보를 저장한다.
- 스택 포인터(SP, Stack Pointer): 스택의 최상위 주소를 저장한다.
- 베이스 포인터(BP, Base Pointer): 스택의 최하위 주소를 저장한다.(기준 주소)
프로그램 카운터 → 메모리 주소 레지스터 → 메모리 읽기(제어신호)가 제어버스 / 메모리 주소 레지스터 값이 주소 버스를 통해 메모리로 보내짐 → 데이터 버스를 통해 메모리 버퍼 레지스터로 전달 / 프로그램 카운터 증가되어 다음 명령어 읽을 준비 → 명령어 레지스터
특정 레지스터를 이용한 주소 지정 방식(1): 스택 주소 지정 방식
스택 주소 지정 방식은 스택 포인터(SP) 레지스터를 이용하여 스택의 주소를 지정하는 방식이다.
스택 포인터는 메모리 스택영역의 최상위 부분을 가르킨다.

특정 레지스터 이용한 주소 지정 방식(2): 변위 주소 지정 방식
변위 주소 지정 방식은 프로그램 카운터와 베이스 레지스터를 이용한다.
변위 주소 지정 방식은 오퍼랜드 필드값(변위)과 특정 레지스터를 이용하여 유효 주소를 지정한다.

1. 상대 주소 지정 방식 : 오퍼랜드 필드값(변위)과 프로그램 카운터(PC) 레지스터를 이용하여 유효 주소를 지정한다

2. 베이스 레지스터 주소 지정 방식 : 오퍼랜드 필드값(변위)과 베이스 레지스터(BP) 레지스터를 이용하여 유효 주소를 지정한다.
- 베이스 레지스터의 역할 : 기준 주소
- 오퍼랜드의 역할 : 기준 주소로부터 떨어진 거리

명령어 사이클
우리가 실행하는 프로그램은 수많은 명령어로 이루어져 있고, CPU는 이 명령어들을 하나씩 실행한다.
이때 프로그램 속 각각의 명령어들은 일정한 주기가 반복되며 실행되는데, 이 주기를 명령어 사이클이라고 한다.


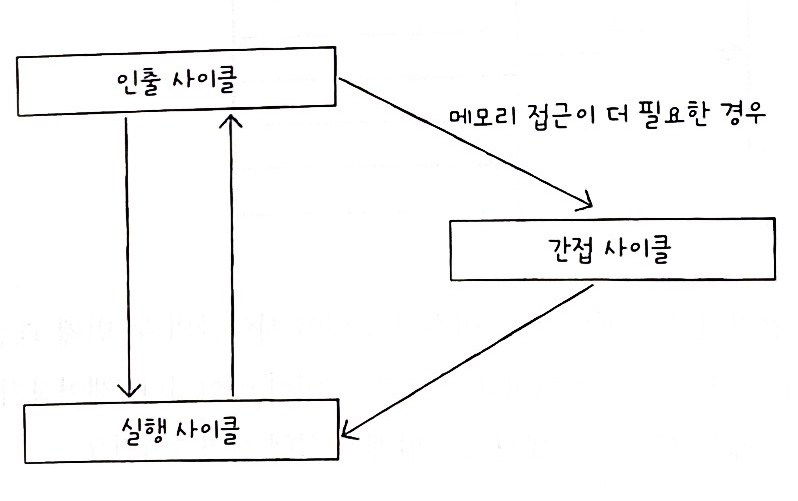
1. 인출 사이클(Fetch Cycle): 명령어를 메모리에서 CPU로 가져온다 (위에 있는 레지스터 읽는 순서)
2. 실행 사이클(Execute Cycle): 명령어를 실행한다.(제어장치가 명령어 레지스터에 담긴 값을 해석하고, 제어 신호를 발생시키는 단계)
3. 간접 사이클(Indirect Cycle): 간접 주소 지정 방식을 사용하는 명령어를 처리하는 과정
- 간접 주소 지정 방식은 오퍼랜드 필드에 유효 주소의 주소를 명시하는데, 이 경우 명령어를 인출해 CPU로 가져와도 바로 실행 사이클을 돌입할 수 없음
- 피연산자의 실제 주소를 찾기 위해 메모리 내의 데이터를 한 번 더 인출하는과정
인터럽트
CPU의 정상적인 작업을 방해하는 신호


- 동기 인터럽트(Synchronous Interrupt): CPU에 의해 발생하는 인터럽트(예외)
- 비동기 인터럽트(Asynchronous Interrupt): 외부 장치(입출력장치)에 의해 발생하는 인터럽트
- 전자레인지 조리 완료, 프린트 출력 완료
하드웨어 인터럽트
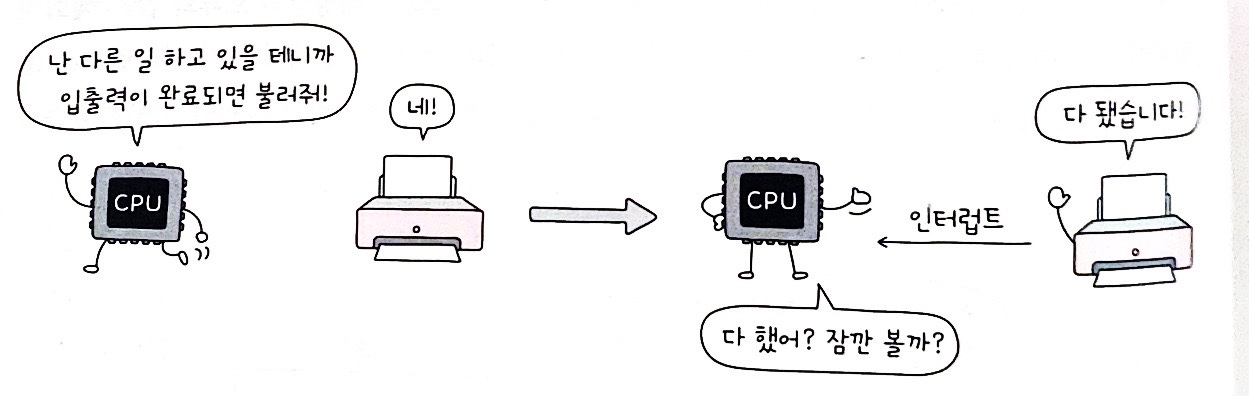
알림과 같은 인터럽트.
CPU가 프린터에 출력을 명령했다고 가정했을 때, 입출력장치는 CPU보다 속도가 현저히 느리기 때문에 CPU는 입출력 작업의 결과를 바로 받을 수 없다. 이때 만약 하드웨어 인터럽트를 사용하지 않는다면 CPU는 프린터의 출력이 완료될때 까지 주기적으로 확인해야 한다.
이로 인해 CPU는 다른 생산적인 일을 할 수 없어서 CPU 사이클 낭비이다. 마치 알림이 없는 전자레인지가 언제 조리를 끝낼지 모르기에 무작정 전자레인지 앞에서 서성이는 것과 같다.
하드웨어 인터럽트의 처리 순서
- 입출력 장치는 CPU에 인터럽트 요청 신호를 보낸다.
- CPU는 실행 사이클이 끝나고 명령어를 인출하기 전 항상 인터럽트 요청 신호를 확인한다.
- CPU는 인터럽트 요청을 확인하고 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 여부를 확인한다.
- 인터럽트를 받아들일 수 있다면 CPU는 지금까지의 작업을 백업한다.
- CPU는 인터럽트 벡터를 참조하여 인터럽트 서비스 루틴을 실행한다.
- 인터럽트 서비스 루틴 실행이 끝나면 CPU는 백업한 작업을 복원한다.
- 인터럽트 요청 신호 : 인터럽트 요청을 CPU에 알리는 신호. 플래그 레지스터의 인터럽트 플래그를 통해 인터럽트 요청을 확인
- 인터럽트 플래그로 막을 수 있는 인터럽트(maskable interrupt)
- 막을 수 없는 인터럽트(non-maskable interrupt)가 있다.
- 인터럽트 서비스 루틴(인터럽트 핸들러): 인터럽트가 발생했을 때 어떻게 처리하고 작동할지 정보를 가진 프로그램
- CPU가 인터럽트를 처리한다 = 인터럽트 서비스 루틴을 실행하고, 본래 수행하던 작업으로 되돌아온다
- 루틴들이 메모리에 저장된다.
- 수많은 인터럽트 서비스 루틴을 구분하기 위해 인터럽트 벡터를 참조하여 실행된다.
- 인터럽트 벡터: 인터럽트 서비스 루틴의 시작 주소를 포함하는 인터럽트 서비스 루틴의 식별 정보
- 인터럽트 벡터 테이블: 인터럽트 벡터를 모아놓은 테이블. 인터럽트 벡터 테이블은 메모리에 저장된다.
예외의 종류
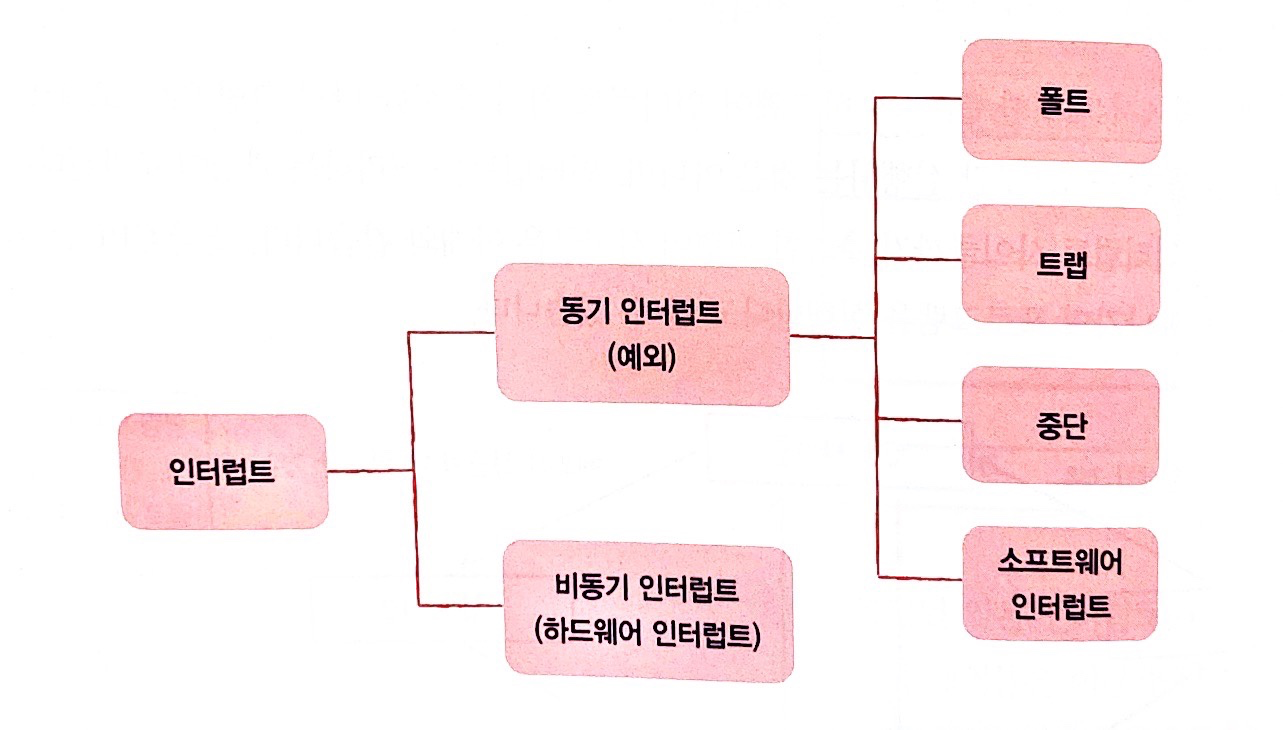
예외가 발생하면 CPU는 하던 일을 중단하고 해당 예외를 처리한 후 본래 하던 작업으로 되돌아와 다시 실행한다.
- 폴트 : 예외를 처리한 직후 예외가 발생한 명령어부터 실행 재개
- e.g) CPU가 한 명령어를 실행하기 위해 꼭 필요한 데이터가 메모리가 아닌 보조기억 장치에 있다고 가정했을때, 프로그램을 실행하려면 반드시 메모리에 저장되어 있어야하기 때문에 CPU는 폴트를 발생시키고 보조기억장치로부터 피요한 데이터를 메모리로 가져와 저장한다.
- 트랩 : 예외를 처리한 직후 예외가 발생한 명령어의 다음 명령어부터 실행 재개
- e.g) 디버깅할때 특정 코드가 실행되는 순간 프로그램의 실행을 멈추게 할 수 있다.
- 중단 : CPU가 실행 중인 프로그램을 강제 중단 시킬 수 밖에 없는 심각한 오류 발생
- 소프트웨어 인터럽트 : 시스템 호출이 발생했을때
🤔 느낀점
하드웨어 인터럽트하니까 주방용 타이머 산게 생각난다.
생선을 양면 각각 5분씩 굽는데, 5분이 지났는지 확인하기 위해 계속 시계를 보는게 너무 불편해서 타이머를 샀는데.
엄청 편하더라. 사람도 CPU처럼 행동하면 훨씬 효율적으로 일할 수 있는 것 같다.
그런데 지금 나는 공부도 효율적으로 하고 있는걸까?
오퍼랜드 필드와 관련된 주소 지정 방식이 되게 많은 것 같다. 이걸 알아야 하는 이유가 뭘까?
아래는 해당 서적의 인프런 강의에서 질문하고 얻은 답변이다.
안녕하세요, 인프런 AI 인턴입니다.
주소 지정 방식은 명령어가 실제 메모리 상의 어떤 데이터를 참조할지를 결정하는 방법입니다. 프로그래밍 언어 수준이 아니라 기계어나 어셈블리어 수준에서 컴퓨터의 아키텍처에 직접적으로 영향을 받습니다. 이해하신 것처럼, 연산을 수행할 때 해당 연산의 오퍼랜드가 어디에 위치하는지를 명시하는 역할을 합니다.
다양한 주소 지정 방식이 있는 이유는 각 방식이 가진 강점을 활용하여 특정 상황에서 더 효율적인 메모리 접근이나 명령어 실행을 가능하게 하기 위함입니다. 예를 들어, 직접 주소 지정은 오퍼랜드가 특정 메모리 주소를 바로 참조하는 경우 사용되고, 상대 주소 지정은 현재 명령어로부터 상대적인 위치에 있는 데이터를 참조할 때 사용됩니다.
프로그래머는 대게 고수준 언어를 사용하여 프로그램을 작성하므로, 이러한 주소 지정 방식에 직접적으로 관여하지는 않습니다. 하지만 컴퓨터구조나 운영체제를 공부하면서 이러한 내부 동작 원리를 이해하는 것은 컴퓨터의 성능 최적화나 효율적인 프로그래밍, 시스템 설계 등에 중요한 배경 지식을 제공합니다.
오퍼랜드를 어떤 방식으로 저장하고 참조할지는 컴파일러나 어셈블러가 프로그램을 기계어로 변환하는 과정에서 결정되며, 이는 주로 프로그램의 특정 요구 사항이나 최적화 전략에 따라 달라질 수 있습니다. 세진님께서 더 깊이 있게 해당 주제에 대해 공부하고 싶으시다면 컴퓨터 아키텍처나 시스템 프로그래밍 관련 강의나 교재를 참고하시는 것이 좋을 것 같습니다.
컴퓨터 내부 아키텍처 측면에서 이러한 메커니즘을 이해하는 것이 중요하며, 이를 통해 소프트웨어가 하드웨어 위에서 어떻게 동작하는지에 대한 개념을 잡을 수 있습니다. 이러한 지식은 문제 해결이나 시스템 최적화, 성능 분석 등의 작업을 할 때 도움이 됩니다.
프로그래밍 언어와는 직접적인 관련이 없지만, 예를 들어 시스템 프로그래머나 임베디드 시스템 개발자에게는 해당 지식이 필수적일 수 있습니다. 고수준 언어를 사용하는 개발자에게도 기본적인 이해가 성능 튜닝이나 디버깅과 같은 작업을 수행할 때 유용합니다.
'CS > 운영체제' 카테고리의 다른 글
| [혼공컴운] 1주차_Chapter1~3 기본미션 및 선택미션 (0) | 2024.01.06 |
|---|---|
| 혼공 컴퓨터구조 + 운영체제 5. CPU 성능 향상 기법 (Mac M2 코어 개수 확인 방법) (0) | 2024.01.06 |
| 혼공 컴퓨터구조 + 운영체제 3. 소스코드와 명령어 (0) | 2023.12.21 |
| 혼공 컴퓨터구조 + 운영체제 2. 데이터 (0) | 2023.12.20 |
| 혼공 컴퓨터구조 + 운영체제 1. 컴퓨터 구조 시작하기 (1) | 2023.12.20 |



