
Notice
Recent Posts
Recent Comments
Link
개발자는 기록이 답이다
AWS 오토스케일링 (ECS) - Scale Out & Scale In 본문

- ECS 는 오토스케일링 연동이 EC2에 비해 간단합니다. CloudWatch 경보(Alert)와 연동해서 특정 CPU 사용률 기준을 넘으면 스케일 아웃, 스케일 인이 되도록 동작합니다.
- ECS 서비스에서 설정 가능하며 배포 방식은 롤링 배포 방식을 따릅니다.
1. CloudWatch 경보 추가
1) '스케일 아웃'에 대한 경보(Alert)를 생성
- 스케일 아웃에 대한 경보를 생성합니다. 스케일 업이 CPU나 메모리 성능을 올리 반면에 스케일 아웃은 인스턴스의 갯수를 증가 시킵니다.
(1) 경보 생성
- CloudWatch의 경보(Alert)를 클릭 후 모든 경보를 클릭 합니다.
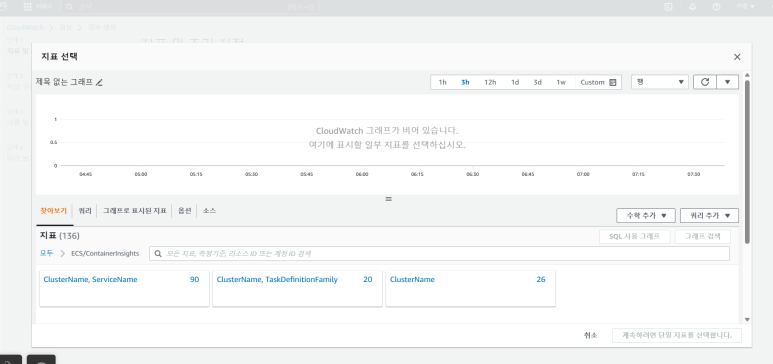
(2) 지표 및 조건 지정 : 지표선택
(3) 사용자 지정 네임스페이스 : ECS/ContainerInsights
(4) ECS/ContainerInsights : ClusterName, ServiceName
(5) ClusterName, ServiceName
-
- ClusterName : cluster-nestjs-02
- ServiceName : service-nestjs4
- 지표 이름 : CpuUtilzed
CPU 사용률을 기반으로 지표를 만듭니다. 특정 CPU 사용률을 초과하는 경우 스케일 아웃 합니다.
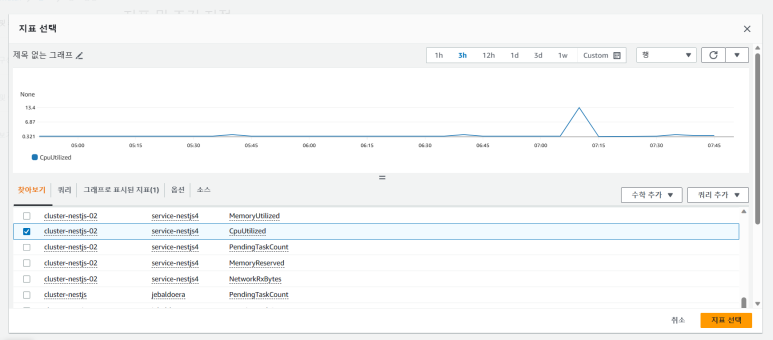
(6) 지표
-
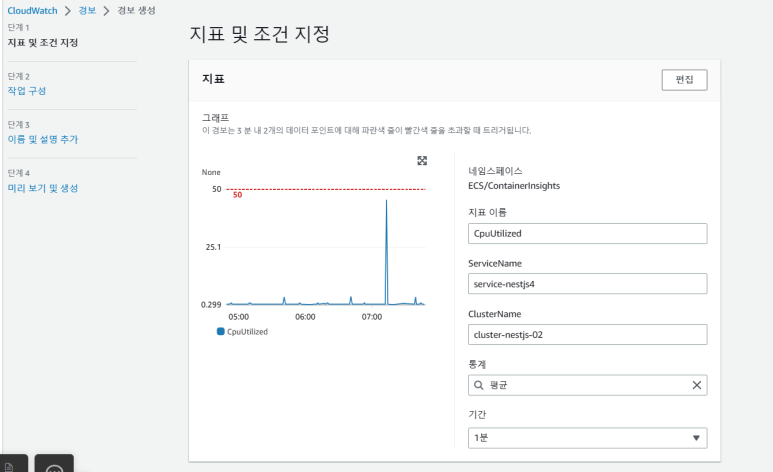
- 지표 이름 : CpuUtilzed
- ServiceName : service-nestjs4
- ClusterName : cluster-nestjs-02
- 통계 : 평균
- 기간 : 1분
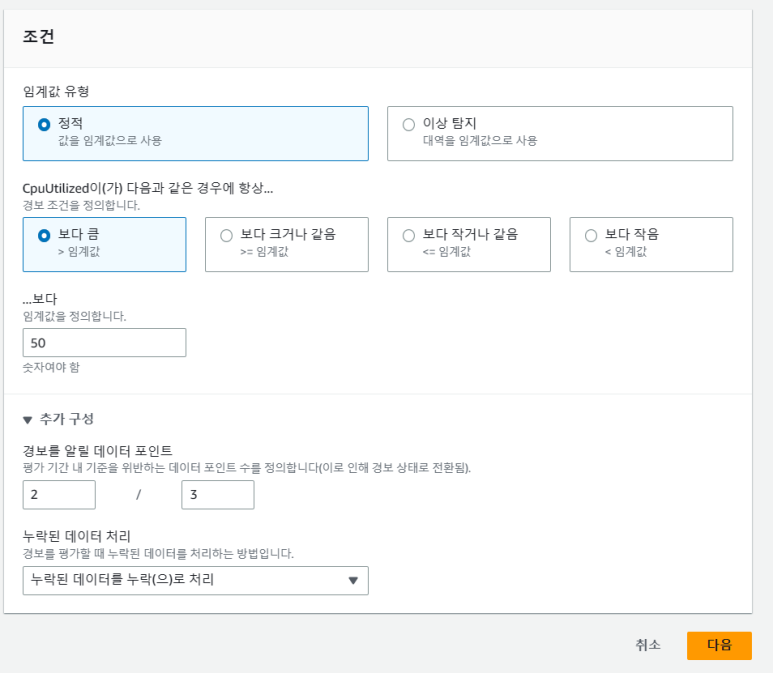
(7) 조건
-
- 임계값 유형 : 정적
- CpuUtilized : 보다 큼
- 임계값 : 50 //CPU 사용률이 50% 보다 클 때
- 추가 구성
- 경보를 알릴 데이터 포인트 : 2 / 3 (조건은 3분 동안 2번 경보가 울릴 때 입니다.)
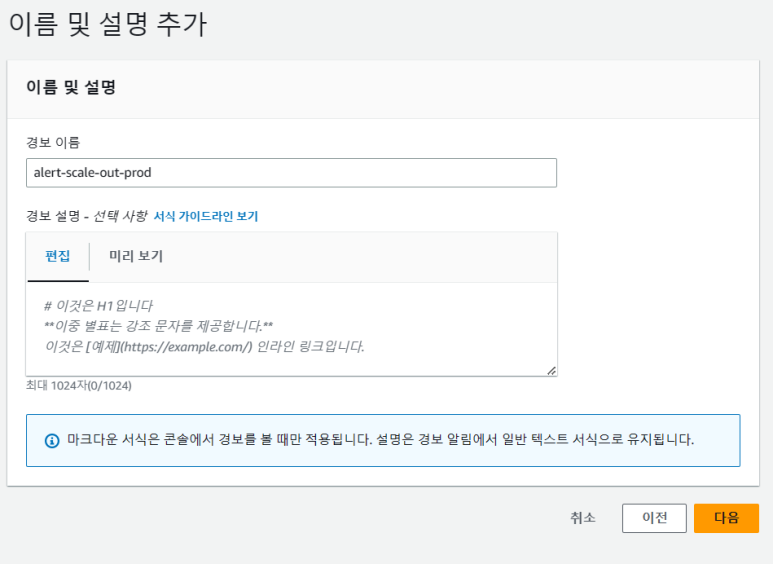
(8) 이름 및 설명 추가
-
- 경보 이름 : alert-scale-out-prod
2) '스케일 인'에 대한 경보(Alert)를 생성
- 스케일 아웃은 인스턴스의 갯수를 증가시키며, 스케일 인은 인스턴스의 갯수를 감소시킵니다. 트래픽이 줄어서 특정 스케일 인 조건을 만족하면 인스턴스의 갯수가 줄어듭니다.
(1) 경보 생성
-
- CloudWatch의 경보(Alert)를 클릭 후 모든 경보를 클릭 합니다.
(2) 지표 및 조건 지정 : 지표선택
(3) 사용자 지정 네임스페이스 : ECS/ContainerInsights
(4) ECS/ContainerInsights : ClusterName, ServiceName
(5) ClusterName, ServiceName
-
- ClusterName : saju-cluster-prod
- ServiceName : saju-service-prod
- 지표 이름 : CpuUtilzed
- CPU 사용률을 기반으로 지표를 만듭니다. 특정 CPU 사용률 미만이면 스케일 인 합니다.(6) 지표
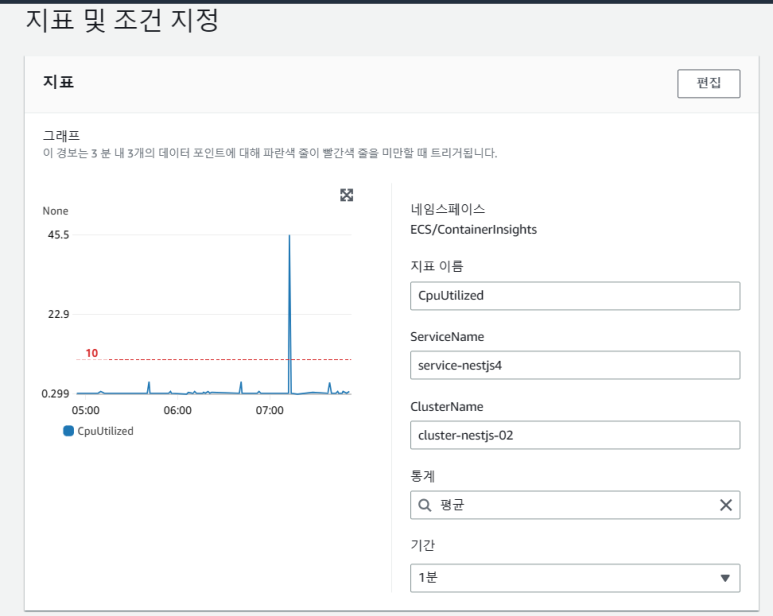
(6) 지표
-
- 지표 이름 : CpuUtilzed
- ServiceName : service-nestjs4
- ClusterName : cluster-nestjs-02
- 통계 : 평균
- 기간 : 1분
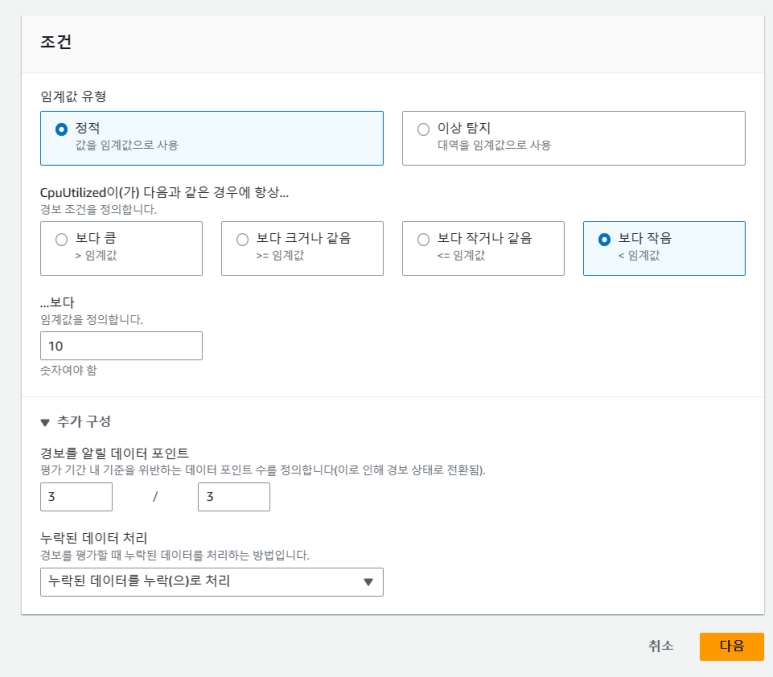
(7) 조건
- 임계값 유형 : 정적
- CpuUtilized : 보다 작음
- 임계값 : 10 //CPU 사용률이 10% 보다 작을 때
- 추가 구성
- 경보를 알릴 데이터 포인트 : 3 / 3 (조건은 3분 동안 3번 경보가 울릴 때 입니다.)
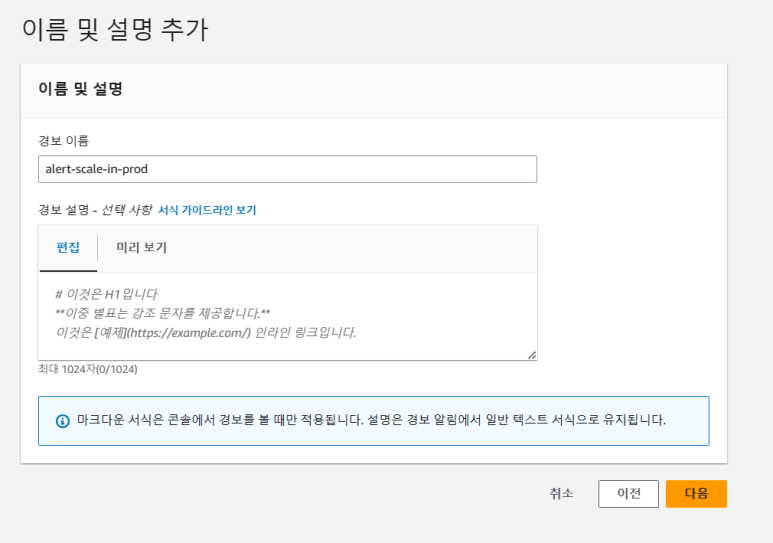
(8) 이름 및 설명 추가
-
- 경보 이름 : alert-scale-in-prod
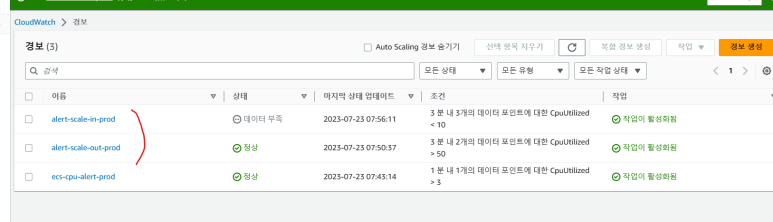
2. CloudWatch 경보 생성 확인
- alert-scale-out-prod, alert-scale-in-prod 경보(Alert)가 생성된 것을 확인 할 수 있습니다.
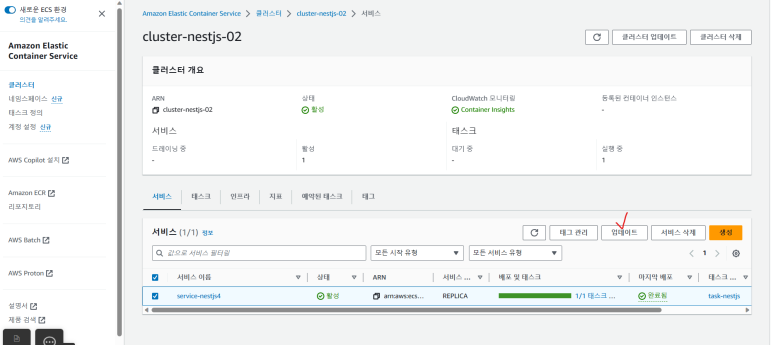
3. ECS 서비스 업데이트
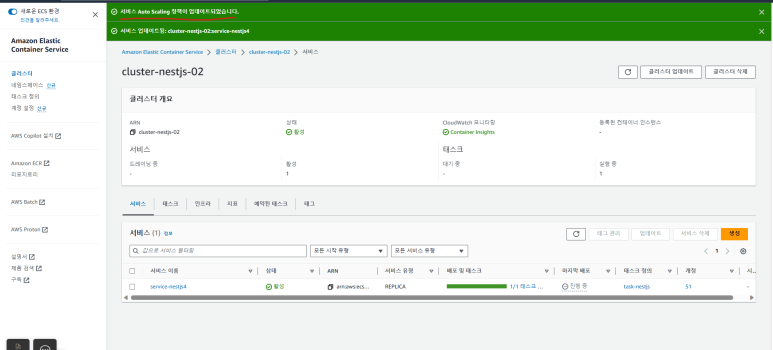
- 위치 : 클러스트 > clust-nestjs-02 > 서비스 > service-nestjs4 선택 > 업데이트
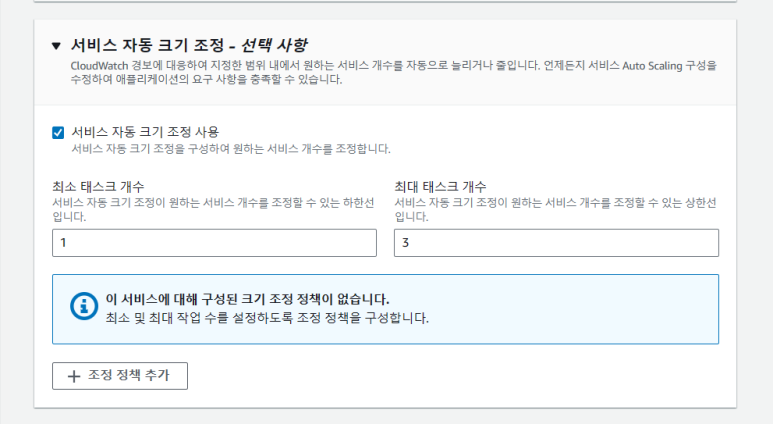
(1) Auto Scaling 선택
서비스 Auto Scaling을 구성하여 원하는 서비스 개수를 조정합니다.
- 최소 작업 개수 : 1 (아무리 트래픽이 줄어도 최소 개수 1개를 유지합니다.)
- 최대 작업 개수 : 3 (아무리 트래픽이 많아도 최대 개수 3개를 넘어가지 않습니다.)
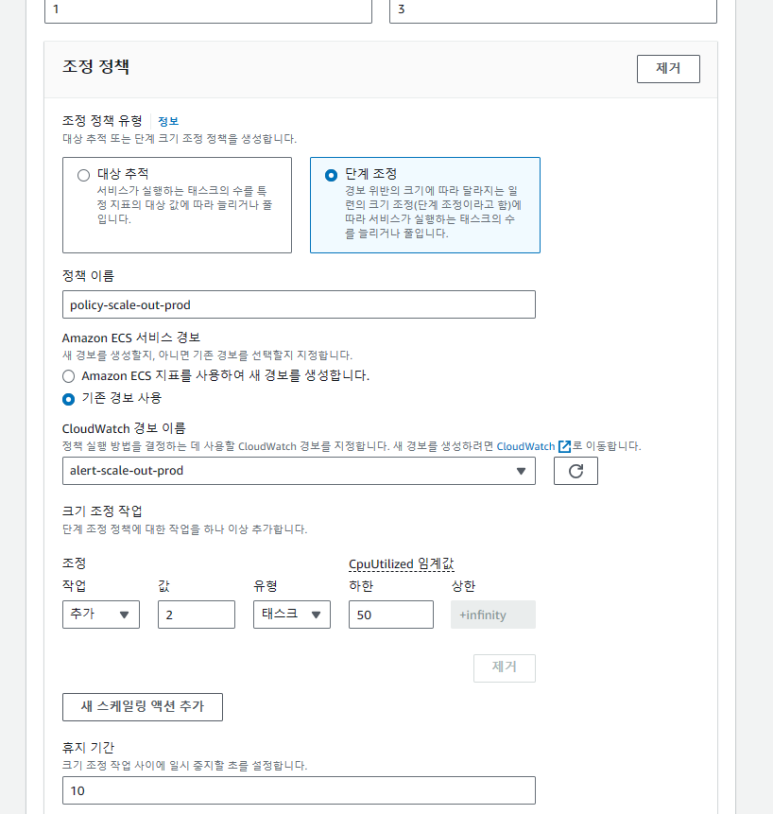
A. 스케일 아웃
-
- 조정 정책 유형 : 단계 조정
- 정책 이름 : policy-scale-out-prod
- 기존 경보 사용 : alert-scale-out-prod
- 조정 작업 : CpuUtilized > 50 인스턴스 2개 추가
- 트래픽이 추세적으로 빠르게 늘어날 수 있기 때문에 2대 씩 증가시킵니다. 그리고 휴지 기간을 300에서 10으로 줄입니다. 휴지 기간은 대기 시간입니다.
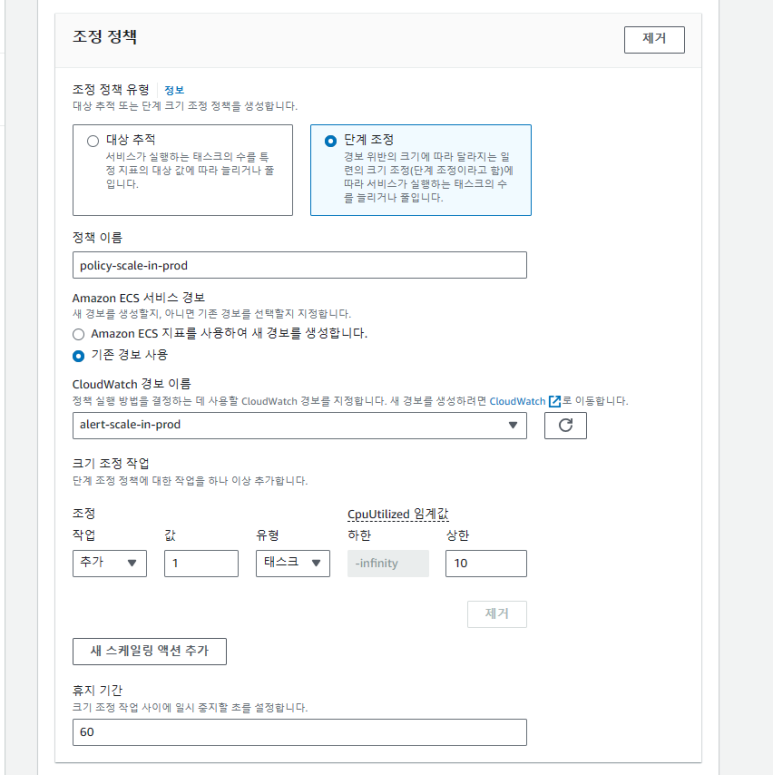
B. 스케일 인
-
- 조정 정책 유형 : 단계 조정
- 정책 이름 : policy-scale-in-prod
- 기존 경보 사용 : alert-scale-in-prod
- 조정 작업 : CpuUtilized < 30 인스턴스 1개 제거
- 트래픽이 일시적으로 줄어든 것 일 수 있기 때문에 1대 씩 감소시킵니다. 그리고 휴지기간을 300에서 60으로 줄입니다. 스케일 인 은 보수적으로 접근해서 트래픽을 처리합니다.
4. Auto Scaling 정책 업데이트 완료
'DevOps > AWS' 카테고리의 다른 글
| AWS CloudWatch 모니터링 대시보드 (0) | 2024.02.28 |
|---|---|
| AWS health check + Slack (0) | 2024.02.28 |
| AWS 스케일링 RDS Scale up & out (수동) (0) | 2024.02.28 |
| AWS 오토스케일링 (ECS) - Scale Up (0) | 2024.02.28 |
| CloudWatch 슬랙 알람1) - AWS Chatbot (0) | 2024.02.28 |
'DevOps/AWS' Related Articles
more



