
개발자는 기록이 답이다
자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비(Sorting and Searching(정렬, 이분검색과 결정알고리즘)_삽입정렬) 본문
자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비(Sorting and Searching(정렬, 이분검색과 결정알고리즘)_삽입정렬)
slow-walker 2023. 10. 1. 14:20
예시 입력 1
6
11 7 5 6 10 9
예시 출력 1
5 6 7 9 10 11
삽입정렬
삽입 정렬(Insertion Sort)은 간단하고 효율적인 정렬 알고리즘 중 하나입니다. 이 알고리즘은 배열을 정렬된 부분과 정렬되지 않은 부분으로 나누고, 정렬되지 않은 부분의 원소를 하나씩 적절한 위치에 삽입하여 정렬합니다. 삽입 정렬은 데이터의 양이 적을 때나 이미 정렬된 부분이 많을 때 효과적입니다.
1. 배열의 첫 번째 원소는 정렬된 부분으로 간주합니다.
2. 두 번째 원소부터 시작하여 현재 원소를 정렬된 부분의 적절한 위치에 삽입합니다.
3. 현재 원소를 정렬된 부분의 적절한 위치에 삽입하면서 다른 원소들을 오른쪽으로 이동시킵니다.
4. 배열의 끝까지 이동한 후, 모든 원소가 정렬됩니다.
// 배열의 두 번째 원소부터 시작하여 현재 원소를 정렬된 부분의 올바른 위치에 삽입하면서 배열을 정렬합니다.
// 이러한 과정을 배열 전체에 대해 반복하면서 정렬을 완료합니다.
public class InsertionSort {
public static void insertionSort(int[] arr) {
int n = arr.length;
for (int i = 1; i < n; i++) {
int currentElement = arr[i];
int j = i - 1;
// 현재 원소를 정렬된 부분의 올바른 위치에 삽입
while (j >= 0 && arr[j] > currentElement) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = currentElement;
}
}
public static void main(String[] args) {
int[] arr = {64, 34, 25, 12, 22, 11, 90};
System.out.println("원래 배열: " + Arrays.toString(arr));
insertionSort(arr);
System.out.println("정렬된 배열: " + Arrays.toString(arr));
}
}
강의 풀이 (Time: 153ms Memory: 27MB)
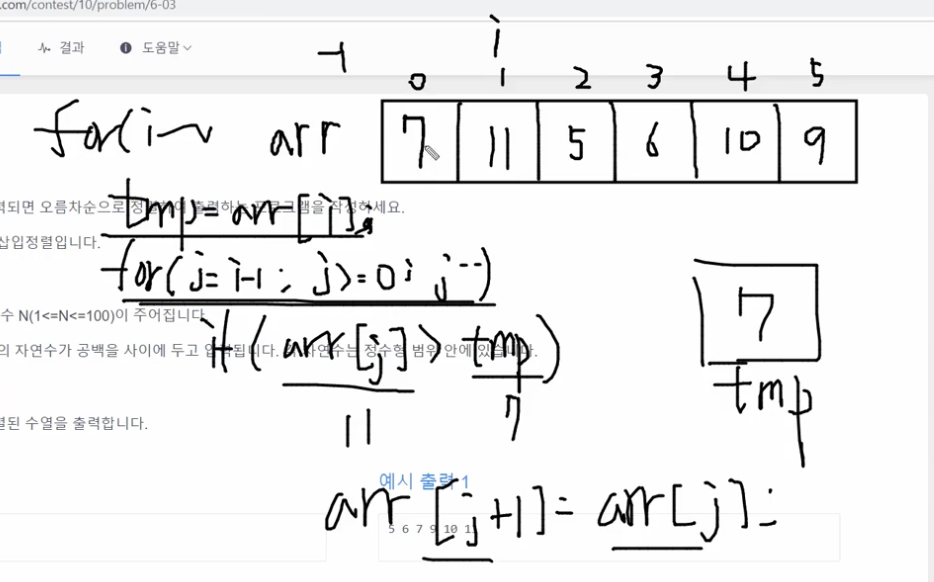
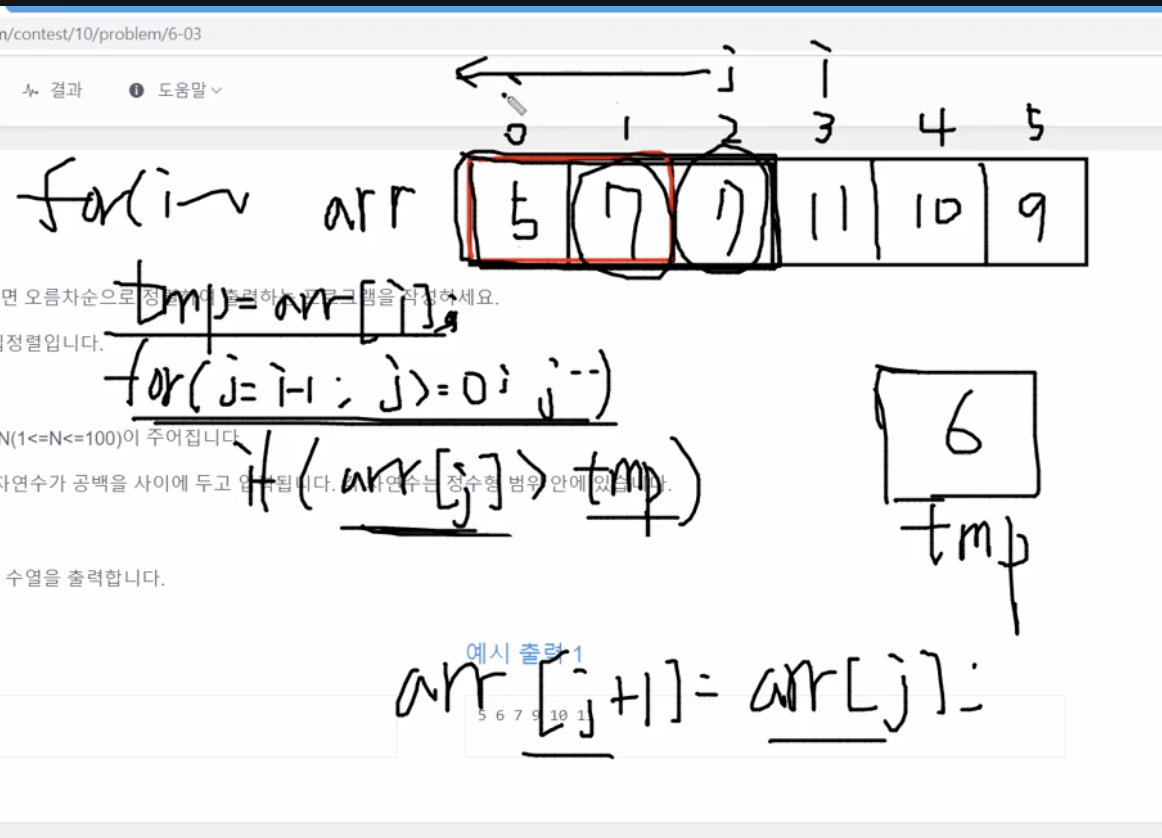
arr이라는 1차원 배열에 입력을 받고, i가 1부터 돕니다. j는 i포문 안에서 i바로 앞에서부터 0까지 하나씩 작아지면서 돕니다.
i for문 안에서 j for문 돌기 전에 tmp변수에 arr[i]를 저장합니다. 그리고 j for문이 돌기 시작하면서 arr[j]가 tmp보다 크면 arr[j]값을 뒤로 밀어주는 것입니다. arr[j+1]지점에 arr[j]를 넣어줍니다.
이렇게 하면 j가 0부터 for문을 돌다가 하나씩 작아지니까 -1되서 for문이 멈출 것입니다. j for문이 멈추고나면 j+1지점에 tmp를 넣습니다. -1에서 멈췄으니까 다시 +1한 0지점에 7이 들어가는 겁니다. (오른쪽 상단 사진)
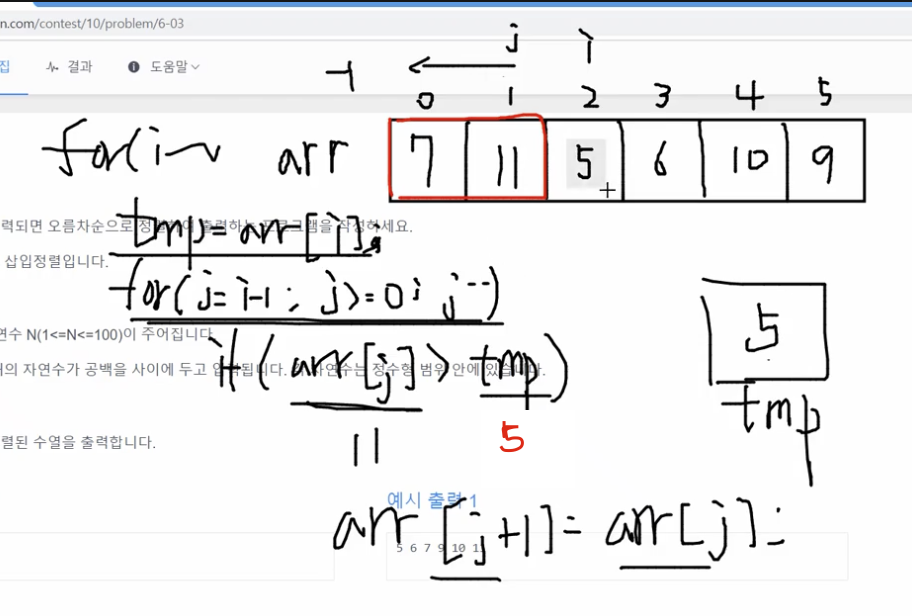
그다음 i가 2번 인덱스로 움직이고, j는 1~0순으로 돕니다. j for문이 돌기전에 arr[i]의 값인 5가 tmp에 재할당됩니다.
arr[j]가 tmp보다 크면 뒤로 미는 것입니다. arr[j]가 1번 인덱스일때 11은 5보다 크니까 뒤로 밀리고, 0번 인덱스일때 7은 5보다 한칸 밀립니다. i가 2인 상태에서 j for문을 끝내면 오름차순으로 정렬이 됩니다.


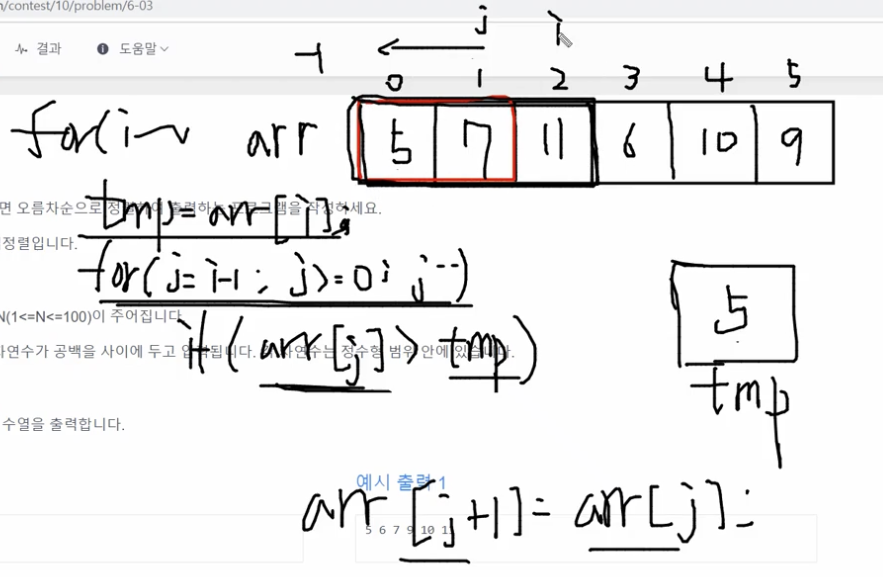
지금까지는 j가 -1이 되었을때 for문을 멈췄는데, 지금부터는 조금 다릅니다. 이제 i가 3이 되었을때를 보겠습니다.
tmp는 arr[i]의 값인 6이 되고, j는 2번 인덱스부터 0번까지 돕니다. arr[j]가 tmp인 6보다 크므로 뒤로 밀리게 됩니다.
그다음엔 1번 인덱스인 arr[j]가 6보다 크므로 뒤로 밀리게 되고, 0번 인덱스일때는 5의 값으로 6보다 작습니다!
arr[j]가 tmp보다 작을 경우 else로 break;해서 j for문을 멈춥니다.
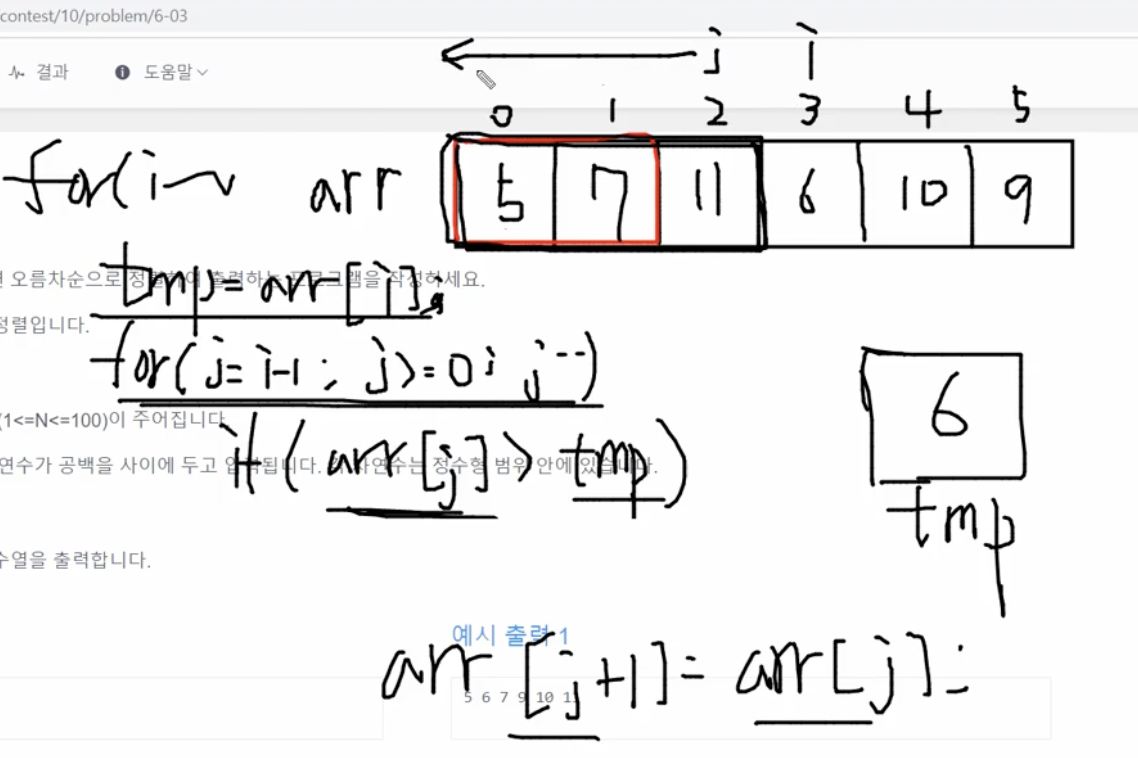


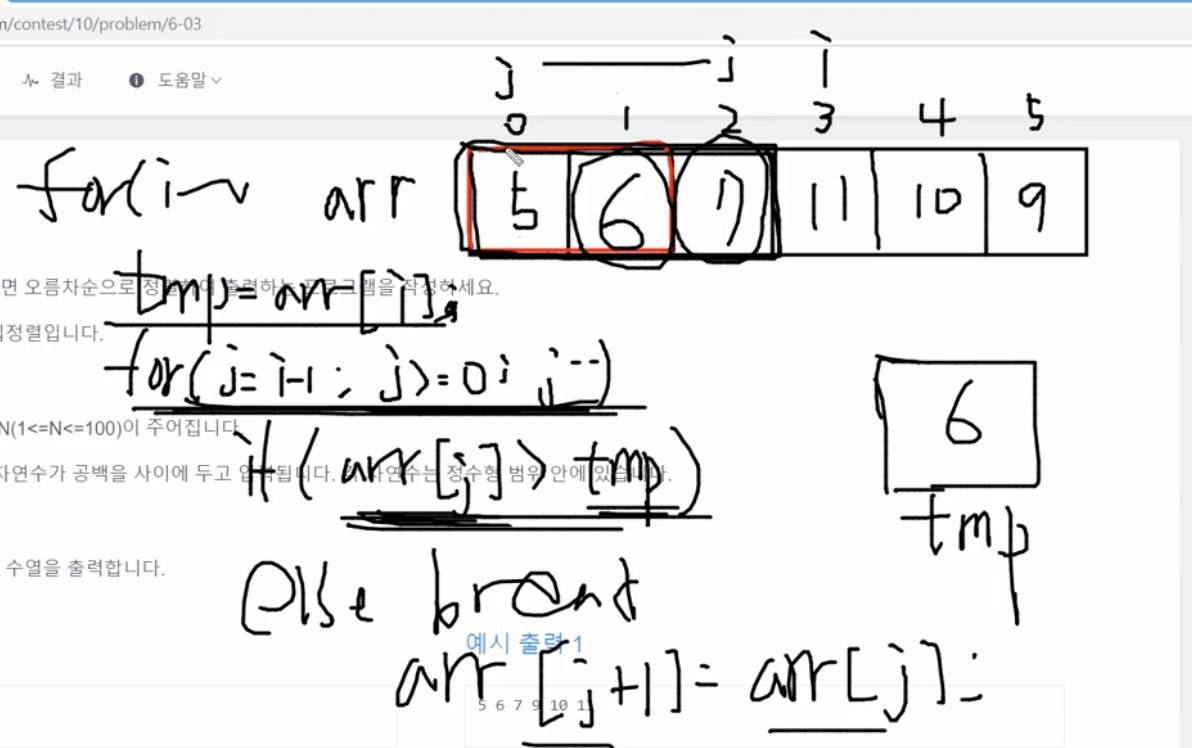
항상 jfor문이 멈춘 바로 뒤편에다가 tmp를 삽입하는 것입니다!
import java.util.Scanner;
public class Main {
public int[] solution(int n, int[] arr ) {
for (int i = 1; i < n; i++) {
int tmp = arr[i], j;
// for문 안에서 j를 선언하면 함수 내부만 지역변수 스코프이므로 for문 밖에서 사용을 못함
// 그래서 j for문 돌기전에 선언
for (j = i-1; j >= 0 ; j--) {
if (arr[j]>tmp) arr[j+1] = arr[j];
else break;
}
arr[j+1] = tmp;
}
return arr;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
for (int x : T.solution(n, arr)) {
System.out.print(x + " ");
}
}
}
선택 정렬, 버블 정렬, 삽입 정렬의 주요 특징 비교
각 정렬 알고리즘은 특정 상황에서 더 효율적일 수 있으며, 효율성은 데이터의 분포와 크기에 따라 달라집니다.
| 알고리즘 | 평균 시간 복잡도 | 최선 시간 복잡도 | 최악 시간 복잡도 | 공간 복잡도 | 안정성 |
| 선택 정렬 | O(n^2) | O(n^2) | O(n^2) | O(1) | 아님 |
| 버블 정렬 | O(n^2) | O(n) | O(n^2) | O(1) | 예 |
| 삽입 정렬 | O(n^2) | O(n) | O(n^2) | O(1) | 예 |
1. 선택 정렬 (Selection Sort):
- 배열을 반복하면서 현재 위치에서 최소값을 찾아 정렬된 부분의 끝으로 이동시킵니다.
- 시간 복잡도는 항상 O(n^2)이며, 안정적이지 않습니다.
- 주어진 데이터의 크기가 작거나 이미 대부분 정렬된 상태일 때 효율적입니다.
- 정렬된 데이터에서도 비효율적으로 동작하므로 안정 정렬이 필요하지 않고 작은 데이터셋에서만 사용하는 것이 좋습니다.
2. 버블 정렬 (Bubble Sort):
- 인접한 두 원소를 비교하고 필요한 경우 교환하여 큰 값을 오른쪽 끝으로 이동시킵니다.
- 시간 복잡도도 항상 O(n^2)이며, 최선의 경우에도 불구하고 여전히 비효율적입니다. 안정적인 정렬 알고리즘 중 하나입니다.
- 정렬할 데이터가 거의 정렬되어 있는 경우에는 선택 정렬보다 성능이 더 나을 수 있습니다.
- 거의 정렬된 데이터셋에서 사용할 때 최선의 선택이 될 수 있으나 일반적인 상황에서는 다른 정렬 알고리즘을 고려하는 것이 좋습니다.
3. 삽입 정렬 (Insertion Sort):
- 현재 원소를 정렬된 부분의 올바른 위치에 삽입하면서 배열을 정렬합니다.
- 최선의 경우 (이미 정렬된 배열) O(n)의 시간 복잡도를 가지며, 평균 및 최악의 경우에도 O(n^2)의 시간 복잡도를 가집니다. 안정적인 정렬 알고리즘 중 하나입니다.
- 데이터셋이 상대적으로 작거나 이미 대부분 정렬된 경우 효율적입니다.
- 데이터가 이미 정렬되어 있는 경우에는 최선의 알고리즘 중 하나이며, 작은 데이터셋에서 빠른 정렬이 필요한 경우에도 적합합니다.
선택 정렬과 버블 정렬은 일반적으로 대규모 데이터셋에서는 효율적이지 않으며, 이러한 경우에는 퀵 정렬(Quick Sort) 또는 병합 정렬(Merge Sort)과 같은 더 효율적인 정렬 알고리즘을 고려해야 합니다. 따라서 정렬 알고리즘을 선택할 때 데이터 크기, 데이터 분포, 안정성 요구사항 등을 고려하여 적절한 알고리즘을 선택하는 것이 중요합니다.



