
개발자는 기록이 답이다
자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비(Hash, sliding window_매출액의 종류) 본문
자바(Java) 알고리즘 문제풀이 입문: 코딩테스트 대비(Hash, sliding window_매출액의 종류)
slow-walker 2023. 9. 29. 23:17

3. 매출액의 종류(Hash, sliding window)
예시 입력 1
7 4
20 12 20 10 23 17 10예시 출력 1
3 4 4 3
내가 푼 틀린 풀이(Time: 1979ms Memory: 35MB) - Time Limit Exceeded
해쉬랑 슬라이딩 윈도우 사용하면 된다그래서, 해쉬셋을 사용했는데, 시간 초과가 나왔다.
입력값이 10만 이상이면 명시적으로 하나의 for문이라도 rt를 이전으로 옮겨서 다시 for문을 돌게 해서 시간 초과가 나는 것 같다.
시간 초과 문제는 rt와 lt를 조작하여 슬라이딩 윈도우를 이전으로 돌리는 부분에서 발생하는 것 같다. 주어진 코드에서 rt와 lt를 이동시키면서 슬라이딩 윈도우를 관리하면 결국 중첩된 for 루프처럼 되는데, 입력값이 커질수록 시간 복잡도가 크게 증가하여 시간 초과 오류가 발생하게 된다.
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Scanner;
public class Main {
public List<Integer> solution(int n, int k, int[] arr) {
int lt = 0;
HashSet<Integer> set = new HashSet<>();
List<Integer> list = new ArrayList<>();
for (int rt = 0; rt < n; rt++) {
if (rt-lt+1 > k) {
lt ++;
list.add(set.size()); // 여태까지 set에 담은 거 list에 사이즈 저장
set.clear(); // set 초기화
// rt에 증가한 lt를 대입해서 다시 이전부터 for문 돌게함
rt = lt;
}
set.add(arr[rt]);
}
// 남아있는 set 담기
list.add(set.size());
return list;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int k = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
for (int x : T.solution(n,k,arr)) {
System.out.print(x + " ");
}
}
}
강의 풀이(Time: 1311ms Memory: 38MB)
HashSet이 아니라 HashMap을 사용해서 풀었다.
HashSet을 이용하면 매출액의 종류를 구하는 방법은 가능하지만, 슬라이딩 윈도우 방식으로 문제를 풀기에는 어렵다.
내가 푼 틀린 풀이는 시간초과가 나서, 다른 방식으로 푸러보려고 했는데, HashSet은 요소의 중복을 허용하지 않기 때문에 슬라이딩 윈도우 내에서 중복된 매출액을 처리하기가 어렵다.
예를 들어서 lt를 움직여서 set에서 제거할때, lt랑 rt사이에 중복된 원소가 있을 경우 set에서 같이 지워져서 슬라이딩 윈도우 구현이 어려워진다. HashSet대신 HashMap을 이용해서 카운트 관리를 하는게 더 효율적이다.
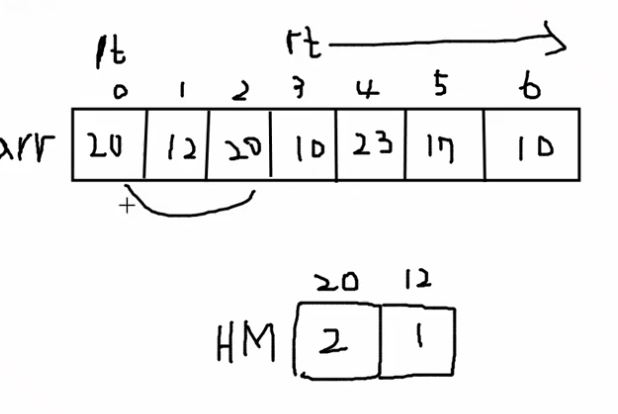
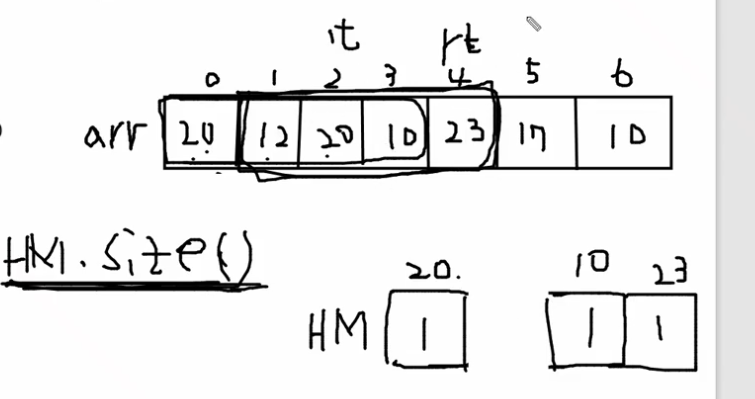
lt는 0이고, k가 4니까 rt는 k-1로 시작하는걸로 세팅한다.
다시 말해서, k가 4니까 3일까지만 먼저 해시맵에다가 세팅해놓는다. 4일째부터 for문을 돌면 된다.
먼저 3바퀴 (k-1바퀴) 정도 돌면서 먼저 세팅해놓고 그 다음에 투포인터로 rt가 돌면서 lt가 쫗아오는 포문을 돕니다.
먼저 3개를 고정시켜놨으니까, 구간이 4개인지 확인하지 않고, 하나 넣고 하나 빼는 방식으로 슬라이딩 윈도우를 하면 됩니다.
가르키는 곳의 key의 value가 0이면 지워야 한다.
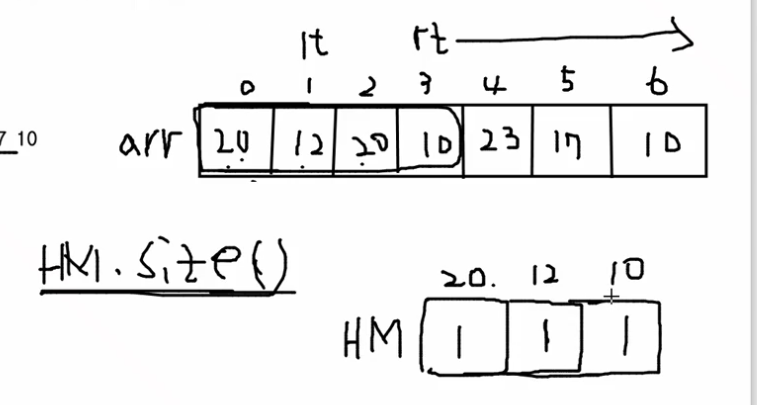
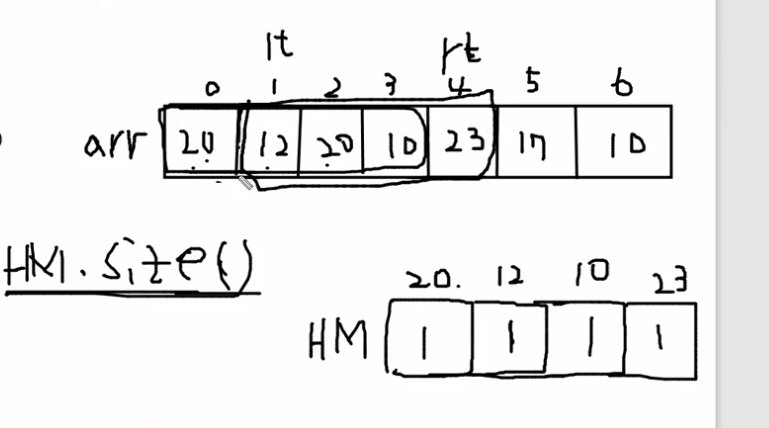
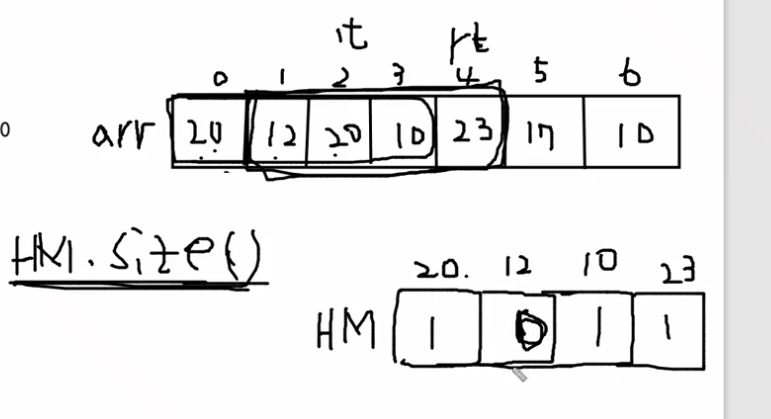
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Scanner;
public class Main {
public ArrayList<Integer> solution(int n, int k ,int[] arr) {
ArrayList<Integer> answer = new ArrayList<>();
HashMap<Integer, Integer> HM = new HashMap<>();
// 초반 카운팅 세팅(k-1바퀴 만큼)
for (int i = 0; i < k-1; i++) {
HM.put(arr[i], HM.getOrDefault(arr[i], 0)+1);
}
// 투포인터 알고리즘
int lt = 0;
for (int rt = k-1; rt < n; rt++) {
// 세팅된 것 중에 key값이 없으면 새로 만들고, 있으면 카운팅 +1
HM.put(arr[rt], HM.getOrDefault(arr[rt], 0)+ 1);
answer.add(HM.size());
// 기존에 있던 key의 value값 카운팅빼기
// 윈도우에서 벗어나기 때문에 빼는 것이다. 빼고 증가!! (22~24 line)
HM.put(arr[lt], HM.get(arr[lt])-1);
// 빼고나서 value가 0이면 키 삭제! - size()에 포함되기 때문이다
if (HM.get(arr[lt]) == 0) HM.remove(arr[lt]); // 키 삭제
lt++;
}
return answer;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int k = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
for (int x : T.solution(n,k,arr)) {
System.out.print(x + " ");
}
}
}
슬라이딩 윈도우 VS 투포인터
- 슬라이딩 윈도우 : 특정 범위 내에서 연속된 요소를 처리하는 기법
- 투 포인터 : 2 개의 포인터(인덱스)를 사용하여 배열 또는 리스트내에서 요소를 조작하고, 정렬된 데이터에서 사용된다. 투포인터를 사용하면 배열이나 리스트를 한 번만 순회하면서 원하는 조건을 만족시키는 요소를 찾는데 효과적이다.
HashSet vs HashMap
자바에서 해쉬라고 하면 해쉬맵(HashMap)과 해쉬셋(HashSet) 두 가지 주요 데이터 구조가 있습니다. 이 두 구조를 어떻게 선택할지 판단하는 것은 문제의 요구사항과 사용 목적에 따라 다를 수 있습니다. 다음은 선택을 돕는 몇 가지 고려 사항입니다:
1. 중복된 값이 필요한가?
- HashMap: 중복된 키를 허용하지 않고, 각 키와 값의 쌍을 저장합니다.
- HashSet: 중복된 값을 허용하지 않고, 값을 저장합니다. 중복된 값이 필요하지 않은 경우 해쉬셋을 선택할 수 있습니다.
2. 데이터의 연관성이 필요한가?
- HashMap: 각 키와 값이 서로 연관된 정보를 저장할 때 사용합니다. 예를 들어, 이름과 나이를 연결하는 경우 해쉬맵을 사용할 수 있습니다.
- HashSet: 데이터의 연관성이 필요하지 않고, 중복을 방지하고자 할 때 사용합니다.
3. 데이터의 접근 방식이 어떤가?
- HashMap: 특정 키를 기반으로 값을 검색하고자 할 때 사용합니다. 키를 사용하여 값을 찾을 때 유용합니다.
- HashSet: 값이 어떤 순서로 저장되어 있는지에 관심이 없고, 값의 존재 여부만 판단하고자 할 때 사용합니다.
4. 메모리 사용량과 성능 고려사항:
- HashMap: 각 키와 값의 쌍을 저장하므로 메모리 사용량이 더 크고, 일반적으로 해쉬 함수를 사용하여 값을 찾으므로 상대적으로 느릴 수 있습니다.
- HashSet: 값만 저장하므로 메모리 사용량이 작고, 값의 존재 여부를 빠르게 확인할 수 있습니다.
알고리즘을 풀 때는 문제의 성격과 요구사항에 따라 해쉬맵 또는 해쉬셋을 선택합니다. 예를 들어, 중복된 값을 저장하고 관리해야 하는 경우 해쉬셋이 유용하며, 키와 값의 연관성을 관리해야 하는 경우 해쉬맵을 사용할 수 있습니다. 문제의 복잡성과 특성에 따라 선택하게 됩니다.



